On the 10th February the Royal Statistical Society Data Science Section were delighted to host a fireside chat with Andrew Ng, who shouldn’t need any introduction!
One of the great benefits of lockdown for me is the time I have to catch up on some of the papers released that are not directly related to my day to day work. In the past week I’ve been catching up on some of the more general outputs from NeurIPS 2020. One of the papers that really caught my eye was “Ultra-Low Precision 4-bit Training of Deep Neural Networks” by Xiao Sun et al.
It’s no doubt that AI in its current form takes a lot of energy. You only have to look at some of the estimated costs of GPT-3 to see how the trend is pushing for larger, more complex models with larger, more complex hardware to get state of the art results. These AI super-models take a tremendous amount of power to train, with costs out of the reach of individuals and most businesses. AI edge computing has been looking at moving on going training into smaller models on edge devices, but to get the accuracy and the speed, the default option is expensive dedicated hardware and more memory. Is there another way?
What does this even mean and why are people putting it on their CVs? 🙂
Towards the end of 2020 I was lucky enough to be hiring for several new positions in my team1. Given the times that we are in, there are many more applicants for roles than there was even a year ago. I’ve spoken before about the skills that you need to get a role as a data scientist and there are specific things I expect to see so I can judge experience and competency when I’m looking at these pieces of paper so I can decide who I want to interview.
Sadly I’m seeing a lot of cringeworthy things on CVs that are the fastest way to put a candidate on the no pile when they reach me. These things might get you past HR and also past some recruitment agents, and I wonder if this is why candidates do them. I try and give as much feedback as I can, although sometimes the sheer volume of CVs and the time taken for constructive feedback would be more than a full time job. By sharing some of these things more publicly I hope to pass this advice on to as many as possible.
It’s been possible to run Linux on Windows for a few years now. Windows Subsystem for Linux (WSL) was released in 2016, allowing native Linux applications to be run from within Windows without the need for dual boot or virtual machine. In 2019 WSL2 was released, providing a better architecture in terms of the kernel and improving the native support. A few weeks ago, Microsoft and NVIDIA announced GPU support on WSL2 and the potential for CUDA accelerated ML on Ubuntu from within Windows. Before I dive into this in detail, I want to take a quick aside into why you might want or need to do this…
There’s a trend in job descriptions that the company may be looking for “Data Science Unicorns”, “Python Ninjas”, “Rockstar developers”, or more recently the dreaded “10x developer”. When companies ask this, it either means that they’re not sure what they need but they want someone who can do the work of a team or that they are deliberately targeting people who describe themselves in this way. A couple of years ago this got silly with “Rockstar” to the point that many less reputable recruitment agencies were over using the term, inspiring this tweet:
To really confuse recruiters, someone should make a programming language called Rockstar.
Many of us in the community saw this and smiled. One man went further. Dylan Beattie created Rockstar and it has a community of enthusiasts who are supporting the language with interpreters and transpilers.
While on lockdown I’ve been watching a lot of recordings from conferences earlier in the year that I didn’t have time to attend. One of these was NDC London, where Dylan was giving the closing session on the Art of Code. It’s well worth an hour of your time and he introduces Rockstar through the ubiquitous FizzBuzz coding challenge.
Recorded at NDC London 2020
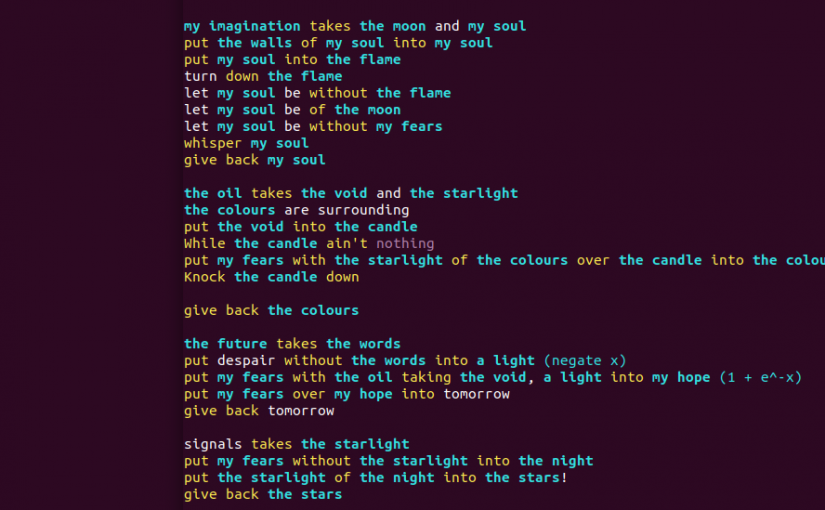
After watching this I asked the question to myself, could I write a (simple) neuron based machine learning application in Rockstar and call myself a “Rockstar Neural Network” developer?
Developer d20 gives the answer 🙂 (from Pretend Store)
If you’ve been to any of my technical talks over the past year or so then you’ll know I’m a huge advocate for running AI models as api services within docker containers and using services like cloud formation to give scalability. One of the issues with this is that when you get problems in production they can be difficult to trace. Methodical diagnostics of code rather than data is a skill that is not that common in the AI community and something that comes with experience. Here’s a breakdown of one of these types of problems, the diagnostics to find the cause and the eventual fix, all of which you’re going to need to know if you want to use these types of services.
In December, Lample and Charton from Facebook’s Artificial Intelligence Research group published a paper stating that they had created an AI application that outperformed systems such as Matlab and Mathematica when presented with complex equations. Is this a huge leap forward or just an obvious extension of maths solving systems that have been around for years? Let’s take a look.
This is part 3 of my summary of ReWork Deep Learning London September 2018. Part 1 can be found here, and part 2 here.
Day 2 of rework started with some fast start up pitches. Due to a meeting at the office I missed all of these and only arrived at the first coffee break. So if you want to check out what 3D Industries, Selerio, DeepZen, Peculium and PipelineAI are doing check their websites. Continue reading ReWork Deep Learning London September 2018 part 3
September is always a busy month in London for AI, but one of the events I always prioritise is ReWork – they manage to pack a lot into two days and I always come away inspired. I was live-tweeting the event, but also made quite a few notes, which I’ve made a bit more verbose below. This is part one of at least three parts and I’ll add links between the posts as I finish them. Continue reading ReWork Deep Learning London September 2018 part 1
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.