This is part 3 of my summary of ReWork Deep Learning London September 2018. Part 1 can be found here, and part 2 here.
Day 2 of rework started with some fast start up pitches. Due to a meeting at the office I missed all of these and only arrived at the first coffee break. So if you want to check out what 3D Industries, Selerio, DeepZen, Peculium and PipelineAI are doing check their websites.
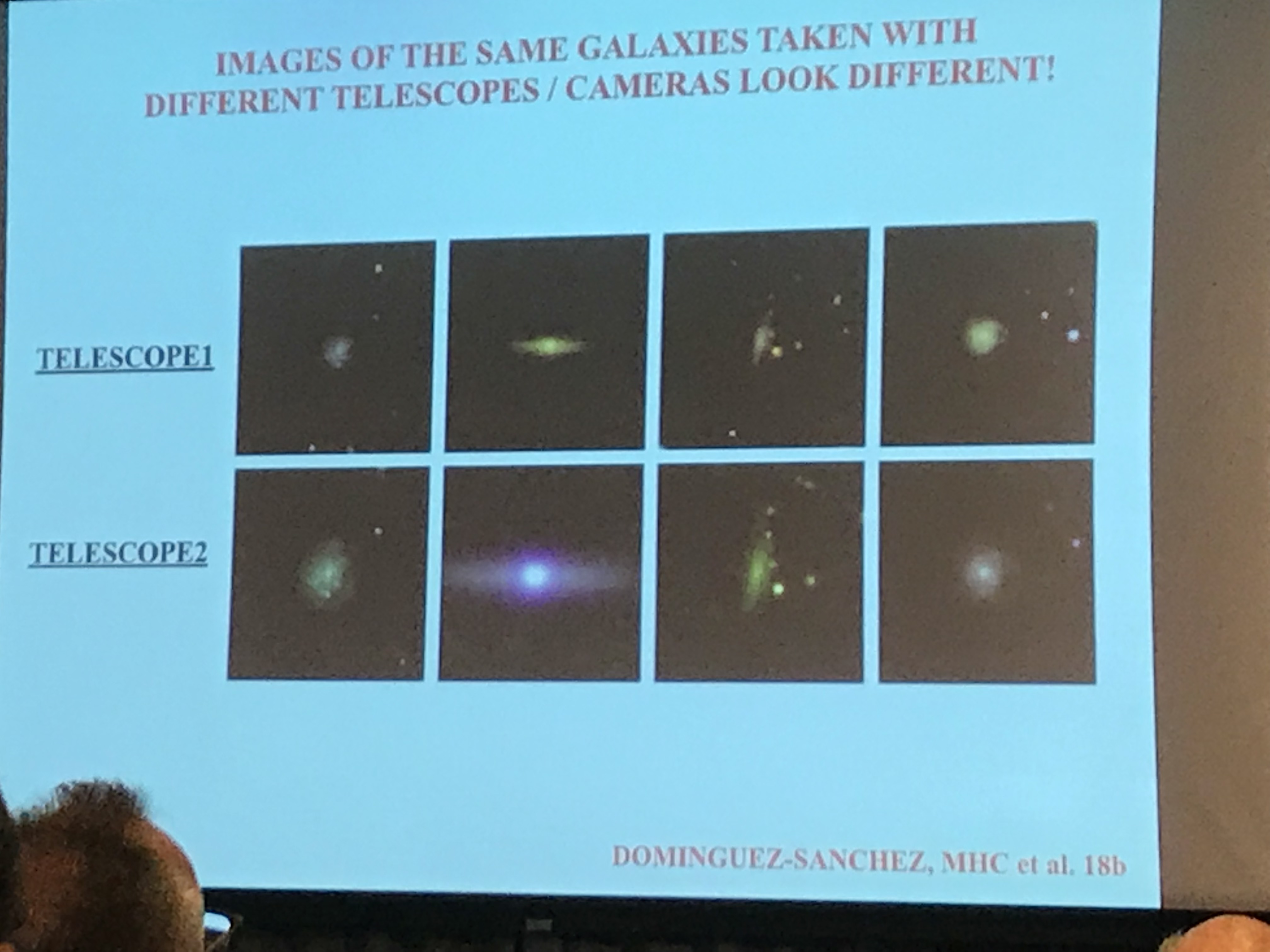
With a large cup of coffee I headed into a talk by Marc Huertas-Company who was discussing the impact of deep learning on astrophysics. He hinted up front that he had a lot to cover and he wasn’t sure he’d get through it all in time and he wasn’t wrong! Starting with some very broad definitions, he explained that galaxies were machines that turned gas into stars and stars were just machines that turned Hydrogen into other elements. We understand the formation and activity of galaxies by observation with telescopes, from which we get images and spectra. Most of the data we have is from under 0.2 square degrees, an area smaller than the moon. There are lots of inherent problems with the data. Most of the pixels are noise and there is a very low signal to noise ratio. The objects have no boundaries, there is a high dynamic range and large dimensionality so analysis is difficult. Big data has arrived to astronomy and with EUCLID it will make all the data gather so far insignificant within a few short years. Far too much for humans to deal with. To tackle this problem they car looking at deep learning techniques within astronomy.
One of the first applications was using citizen scientists to create a labelled data set of galaxies and use this to train a classification network. This had unprecedented accuracy. Using data from Hubble as a test set (which had been hand labelled) they achieved 99% accuracy, which far exceeded previous SVM techniques. There are some challenges with using images from astronomy with neural networks as images of the same galaxy can look very different when taken by different telescopes or cameras. This is a tricky problem and they resolved it using transfer learning. New telescopes needed only 10% of the data to retrain. He then asked if deep learning could go beyond the human eye?Given a snapshot of a galaxy can deep learning predict where it exists on the timeline of the creation of a galaxy? They created objects from a simulation and made them to look like they would be observed by Hubble. These were then classified with a convolutional neural net to 70% accuracy. While not as high as they’d like, this is not something a human eye can distinguish. Marc had many more slides that he had to skip which was a shame, but I’m looking forward to seeing the whole set as many of the challenges they’ve had to overcome could be applicable for the data science community generally.
Next up was Rob Otter at Barclaycard. Similar to the talk from Angel at Santander on day 1, he highlighted the many ways that AI was being used within Barclays: from fraud detection, default prediction for debts, sentiment analysis and image recognition even down to mismatches between observed and known data so that potential security issues can be challenged in real time. Their first models are in production and he said it was challenging deploying them. I’d’ve loved to have talked to him about this more at one of the breaks but didn’t get the opportunity. Barclays have an independent unit that challenges evidence of the AI to make sure each version is rigorous before it goes live. They have 20-30 models in production within the next year, plus rules engines that manage the data, so they need to own their own hardware to manage latency, costs and security. As expected, transferring to GPU from a CPU based system gave a cost saving of 98% (although it wasn’t clear if that was total cost of ownership or running costs only). They have had to build their own custom servers, with 4 GPUs, 100GB ethernet and a direct link to 100TB of SSD memory. I had all sorts of geeky questions about resiliency which he didn’t have time to answer.
We were then straight into the next talk which was a shift in technical detail. Cedric Arcehambea of Amazon was discussing how to train model hyperparameters as an aid to democratising machine learning. The search space is large and diverse and without understanding what you are doing, adjusting hyperparameters can have severe consequences. One of the techniques that has become popular in 2018 is Bayesian Optomisation. Looking at a probabilistic model captures uncertainty and allows convergence to a good solution, balancing exploration of hyperparameter space with exploitation. Can this technique be used for transfer learning? They tried a “warm start” approach by leaving a task out and then training and this worked well on most standard open machine learning data sets. Their paper describes this in more detail and is available on https://arxiv.org/abs/1712.02902

Listening to this talked jogged my memory of the first ReWork conference I attended in Boston in 2015 where Ryan Adams spoke about his spinout Whetlab (acquired by Twitter before I had chance to really test their beta). Checking my notes of 3 and half years ago and yes, Whetlab was also using Bayesian Optimisation (among other techniques) to tune their hyperparameters. Even though Whetlab no longer exists, the papers are still there to read: https://arxiv.org/abs/1502.03492
Cyber security has its own unique challenges and Eli David of Deep Instinct was up next discussing Deep Learning for cyber security. He made a great point that humans are very good at telling the difference between a cat and a dog but when you actually try to describe the difference it’s practically impossible. When it comes to cyber security, files cannot be constrained into specific sized and convolutions don’t work because there are non-local correlations. Also, inferences cannot be cloud based as there is no guarantee of connectivity and it’s essential to avoid latency. They couldn’t use the existing building blocks from the available deep learning frameworks so had to write their own. From scratch. Direct to CUDA. In C. Very impressive. Although Eli did say C was not nice and not convenient – haw dare he besmirch my favourite programming language ;). This worked really well, although it’s not enough to predict that a file is malicious, you also need to say why it’s malicious, so they built a secondary classification network.
In addition to type of malicious attack, it can be important to determine origin of attack. As Eli showed a picture of Putin and Trump his whole slide deck went offline for a second, which was hilarious timing. Quite often, characters from other languages are hidden inside scripts to throw investigations off – what Deep Instinct found was that there was recognisable consistency in programming practises from specific countries and this could be used to find the origin even if it was written in a different language.
I asked how their network performed compared to the research frameworks and although it was an unfair comparison he estimated that their system was about 70% faster on a like for like network. Interesting to see the excess bloat that abstraction adds to the process.
The last two sessions of the day were panel sessions to get us thinking about some of the questions that had been dotted about the venue for the previous two days. The first session was on regulation and global policy. The panel made some excellent points that both too much resistance and too much embracing of new technology can be bad. Forging ahead with no consideration of the impact can be just as damaging (although in different ways) to resisting technology and legislating against it. There was the question of whether robots that were smart enough should be given rights, although this wasn’t explored further. What was discussed mostly was data permissioning – in some senses the public can choose how they want their data to be used by which organisations they trust – we need to do a better job of communicating the advantages of donating data. What was clear is that the US and China are moving quickly while Europe is moving much more slowly. The panel agreed that this needed to be a co-regulatory approach.
The second panel was more ethically focussed and started with the strong statement that GDPR is not an ethics framework, but it can be considered a starting point. Currently companies are making their consent forms over complicated – part of this is to make sure that they have covered themselves legally, but there is definitely an aspect of making it too confusing so that the general viewer will agree rather than have to read everything. They don’t help consumers – we need clear , informed consent. Education is important both on how to communicate and also generally so that people understand what they are signing up to rather than withdrawing all permission. For general ethics of AI systems, the consensus was that it’s really not difficult to include ethical considerations and have these conversations in your company.
After a final round of applause for all the speakers, the conference closed. Lots of great ideas and contacts made all round. I do love the ReWork summits, always something for me to learn and get inspired by, and I’m looking forward to the next one.