This is part 2 of my summary of the Rework Deep Learning Summit that took place in London in September 2018, and covers the afternoon of day 1. Part one, which looks at the morning sessions can be found here.
I’m always fascinated by some of the problems with AI and language. Lucia Specia of University of Sheffield kicked off the afternoon session with a discussion on multimodal, multilingual context models. She started with a recap of some of the problems with ambiguity in language and also the issues with gendered languages and the problems when you are trying to describe something that is not gendered. There was a translation of a headline about a tennis player, which is ungendered in English, that was translated to a masculine noun in French, even though it accompanied a picture that was clearly a female tennis player. There are also issues where a language has multiple words for nuances of the same thing and Lucia gave an example of the German words for stone and rock here. Statistically 14% of machine translation is too literal and human edits are mostly to account for ambiguity or edit for gender. Is it possible to take an image and a caption in English an get a good translation into another language? Real images are too complex and contain far more detail than we would normally describe, so only the relevant parts of the image should be used. In the first experiments, attention and text together actually worked worse than text on its own, which was surprising to me. The next idea was to detect objects and then update the words based on those objects. This gave much better results and pretty much correct attention, but there is still more to be done
Next up was Tom Szumowski of Urban Outfitters who have over 10 million photos that have been very manually tagged. They use AI for trends, forecasting and optimising customer navigation, and also a case study that most businesses wanting to get started in AI want to know the answer to: is it better to use third party vision or custom in house models? He showed an example problem using a small dress data set. The set included items that clearly weren’t dresses (shoes) as well as items that could be mistaken for dresses (long shirts) and attribute labels such as pattern (stripes, solid colour etc). They evaluated Clarifai, Azure, Google and Salesforce. They were also going to evaluate IBM Watson but this was 20 times more expensive that the other options. A great thing to know. They also used three public benchmarks. Since the target customer for these services is a person with no machine learning experience, no preprocessing was done on the images. What was lacking for me was comparison against an expert designed network, but it was great to see this comparison.
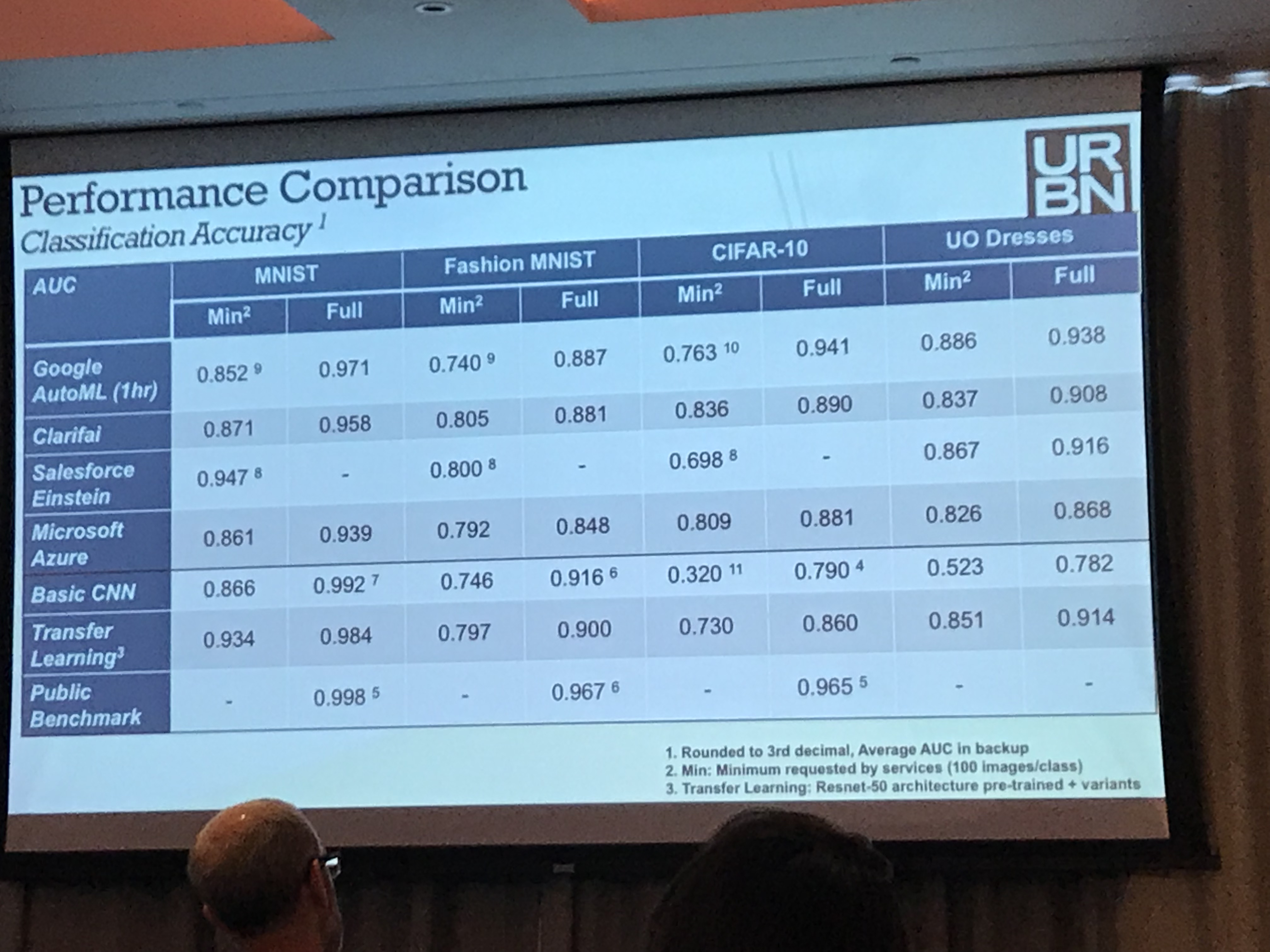
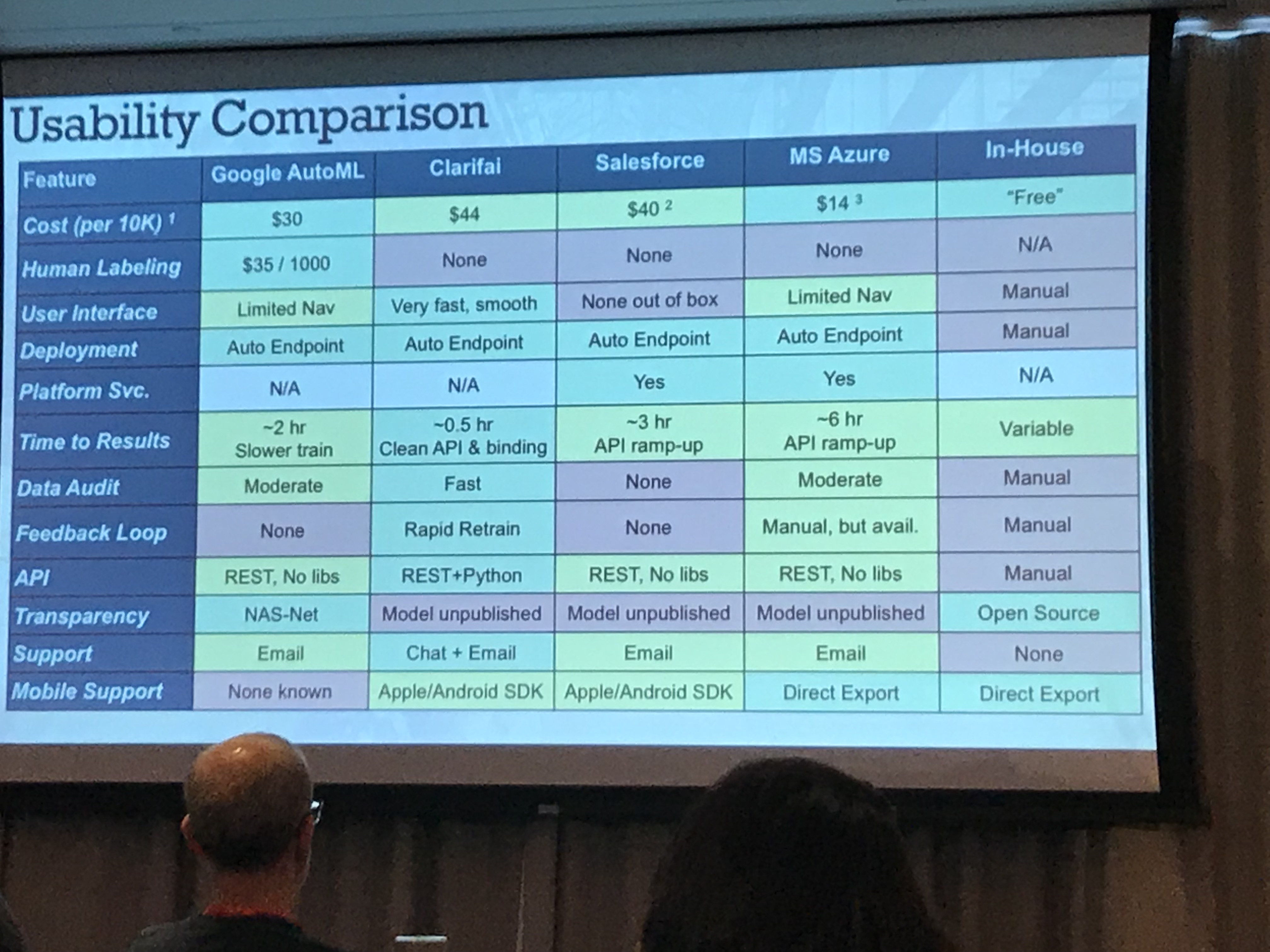
The performance pretty good if you’re not looking for the most precise output and the services lack explainability, which may be an issue. The models can also get confused easily as they’ve not been tuned for specific problems. His final point was that in addition to cost and performance there are many other considerations that may impact which service to use.

After a quick coffee break was Jian Li of Sky discussing content discovery, which is usually achieved my a measure of similarity between two objects. They hypothesised that you could get interesting results by looking at dissimilarity. Films are tagged with multiple concepts, so what is the meaning of combining multiple concepts? Jian Li noted that if you look up a word in a dictionary, it is described only using other words in the same dictionary. They applied the same approach to the movie tags, explaining each tag as a combination of other tags and encoding the relationship between them. Using a tree structure it is possible to navigate from one concept (action thriller) to another (e.g. romantic comedy) and use this flow to provide diverse but relevant content. He showed an example where a hypothetical family was trying to find a compromise between and action film, animated children’s film and a romantic comedy and the offered compromise choices, which was pretty interesting.

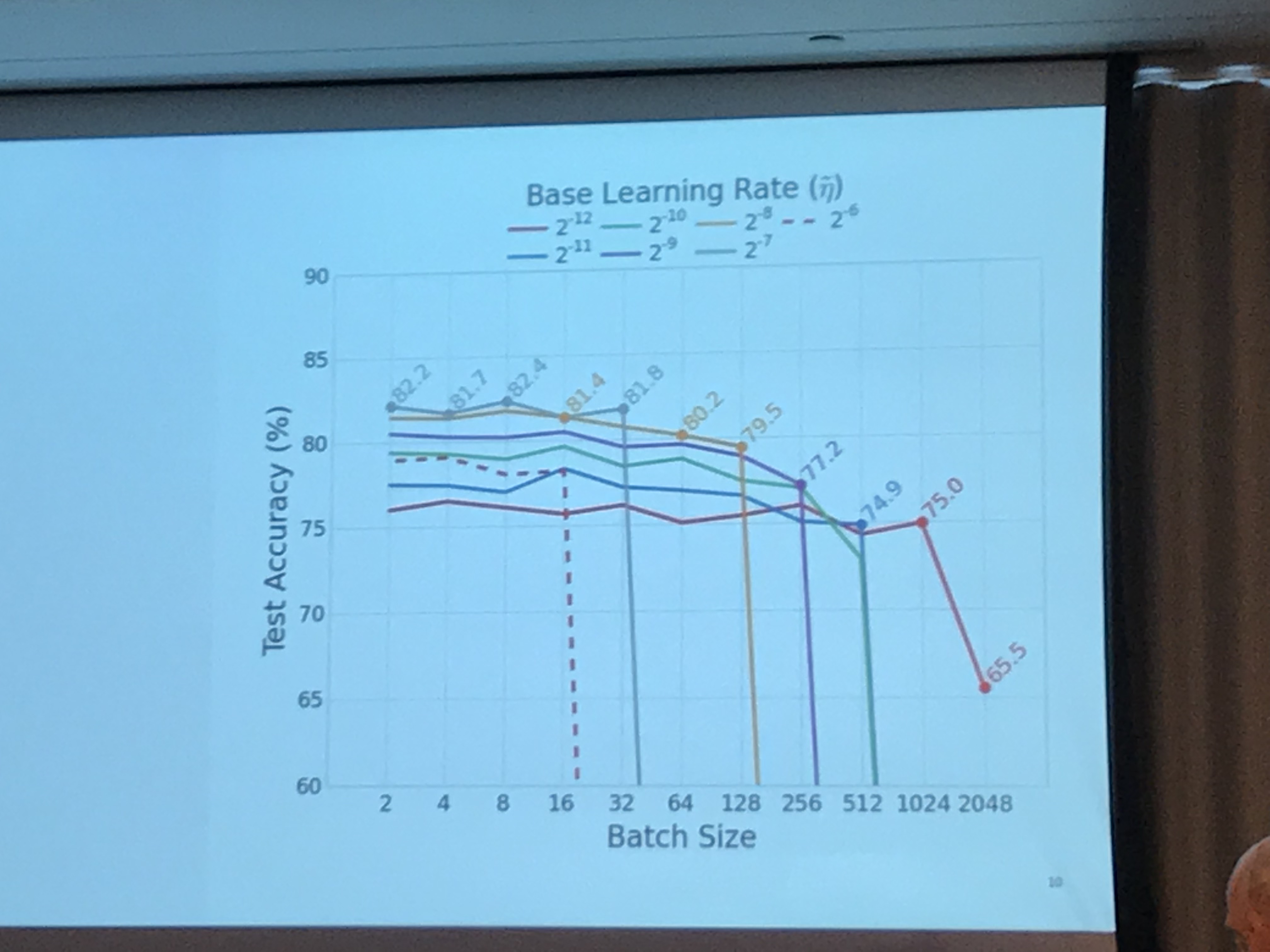
The final theme of the day was that of challenges in deep learning and consisted of three shorter talks kicked off by Dominic Masters of Graphcore and revisiting small batch sizes. After a quick review of batch sizing benefits (larger gives increased parallelism and smaller means lower memory requirements) he discussed their experiments where they fixed epochs and learning rate. However, according to Goyal et al 20171, if you change the batch size then you should scale the learning rate linearly. So learning rate scaling needs to be included in any batch size comparisons. Small batch sizes and smaller learning rates seem to work best for AlexNet, but batch norm has problems on smaller batch sizes. The best results seemed to be on batch sizes of 4 and 8. Ideally you want to use the smallest batch size while maintaining computational efficiency. Much more detail is available in their paper: https://arxiv.org/abs/1804.07612

Next up was Taco Cohen of Qualcomm who was looking at power efficient AI. The human brain is incredibly efficient in its power consumption. The value of AI must exceed its cost to run and in future it will be measured by intelligence per Watt hour. As such it’s critical to make sure that you only use what you need. Particularly on mobile devices where there are both power and thermal ceiling constraints. One of the things they were doing at Qualcomm was using Bayesian deep learning to prune away needless parts of the model. The techniques he went through were pretty much as explained in Zhang and Sun’s 2017 paper https://arxiv.org/abs/1707.06168
The honour of the final talk of day 1 was given to Janahan Ramanan of Borealis who was considering event prediction. He wanted to predict when certain events or actions take place, what behaviour drives their customers and how do they track longer term transitions of their clients? He showed a fingerprint of client spending through time and the different patterns that different habits produced for different items, including outliers. For example, one client bought 7 cars within a three year period. They wanted to know which type of sequencing model was the best to use and, to summarise their experiments, the best thing to do is use all of them and discover the best empirically as they each have different strengths!
With that, day one was done and the networking drinks commenced. Part 3 can be found here.
- I haven’t had chance to look for this paper yet ↩