In September 2016, the ReWork team organised another deep learning conference in London. This is the third of their conferences I have attended and each time they continue to be a fantastic cross section of academia, enterprise research and start-ups. As usual, I took a large amount of notes on both days and I’ll be putting these up as separate posts, this one covers the morning of day 1. For reference, the notes from previous events can be found here: Boston 2015, Boston 2016.
Day one began with a brief introduction from Neil Lawrence, who has just moved from the University of Sheffield to Amazon research in Cambridge. Rather strangely, his introduction finished with him introducing himself, which we all found funny. His talk was titled the “Data Delusion” and started with a brief history of how digital data has exploded. By 2002, SVM papers dominated NIPs, but there wasn’t the level of data to make these systems work. There was a great analogy with the steam engine, originally invented by Thomas Newcomen in 1712 for pumping out tin mines, but it was hugely inefficient due to the amount of coal required. James Watt took the design and improved on it by adding the condenser, which (in combination with efficient coal distribution) led to the industrial revolution1. Machine learning now needs its “condenser” moment.
Neil went on to discuss the Facebook DeepFace recogniser. In the US, all pictures uploaded are being used to augment the engine2, and this is how Facebook are getting the large amounts of data they require. Other big players are also doing this. There was a wonderful analogy of deep learning algorithms to a bagatelle board, with the pins representing the parameters and the training phase moving the pins to get the sorting correct. However, there can be parts of the machine that are never exercised in training and this is where things can go wrong. As I’ve mentioned before, testing is critical.
It’s also critical to note that changes imperceptible to humans can cause major differences in predictions. One solution is to use multiple paths3 although this is very computationally intense as it integrates over all possible paths. Gaussian processes can then reject functions that don’t conform. Some of his latest work is in the Journal of Machine Learning Research . Questions revolved around data democracy – the big players have all the data while other businesses and academics can struggle to get access to the data required to train. This is becoming easier and, since the conference, Google has released data sets for image and videos that are licensed for commercial use. There’s also a lot of work being done on simulated data and how to weight knowledge from simulations against data from the real world (which can be noisy). This is very much a problem for the whole industry.
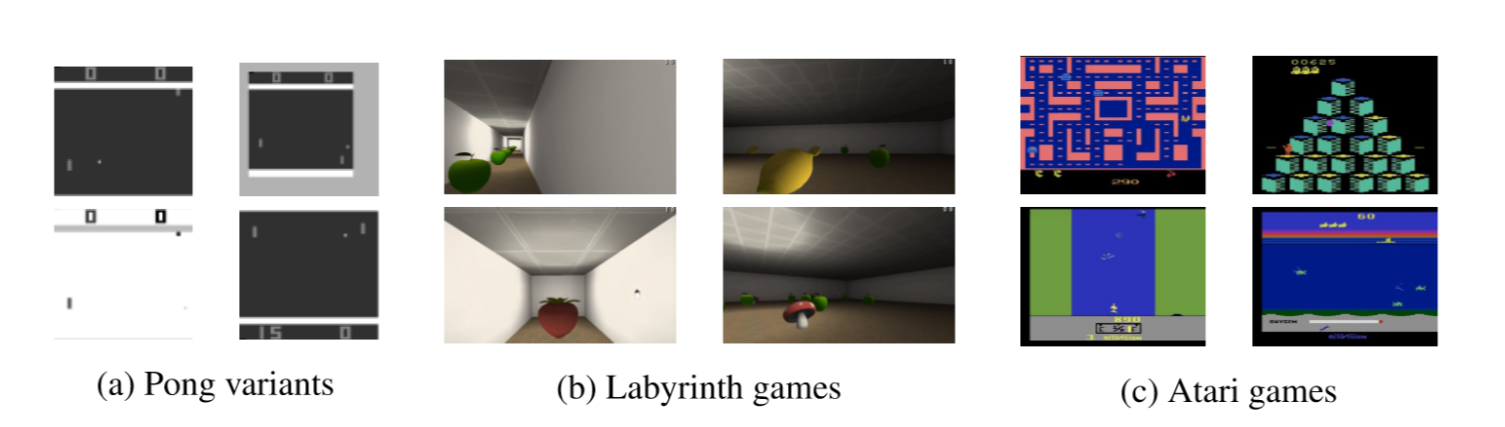
Next up was Raia Hadsell from Google DeepMind who started out in Deep learning back in 2003 when it wasn’t cool4. Her talk was on the adaptability of AI and how learned skills can be transferrable to new tasks. At present, we don’t have networks that can identify objects, playt space invaders and listen to music – there’s a need for a general artificial intelligence. Even just narrowing the problem to video games, there are contradictions to the rules if they are learned together, resulting in low skill attainment accross the board. If learned independently then the networks forgets the rules for previous games. What’s needed is to become expert on multiple tasks, transferring similar skills between tasks. This can be achieved with progressive neural networks. Raia and her team used reinforcement learning to play Qbert, with a three times larger network to produce the final result. For the second task, a second network was used with lateral connections at each layer to the first column. Training the second network included gradient back propagation, preserving the weights from the first network. This meant that the second network could use useful details from the first without losing the ability to play the original game. A third network with lateral connections to both the first two networks was created to learn the third game. The multi-layered network was successful however it was apparent that there would be an exponential growth in connections and tasks, although it is possible that duplicated tasks and boundaries could be pruned to make the final network more efficient.
Raia and team’s test scenarios from https://arxiv.org/pdf/1606.04671v3.pdf
For data, the team used “pong soup” – a combination of visual transformations (black/white and horizontal flips, addition of noise and variations of zooms). The question was how much faster could the game be learned than from just retraining? While the results were not quantitative there was significant transfer. The same techniques could be applied to robotics to create human level skill from raw sensor data. Simulations are only valuable if you can transfer fom simulation to the real world, a problem known as bridging the reality gap. A robotic arm was trained in a reacher task for a static ball with a random start to a random finish. Using a convnet with LSTM and softmax, it took one day to train from RGB inputs to a 6D model. Real robots took approximately 55 days. A second column network was introduced for the real video rather than simulation. There was very fast transfer even though the input domain was very different. With the third column, a new task was created with a falling target and only half an hour was needed to train. The fourth column was added for a further task where the target had random motion and the robotic arm was again sucessful in solving the task quickly. I found that this reinforcement learning has some interesting similarities with human brain development – we do know that human neural plasticity decreases as we age and could be a biological equivalent of the “pruning” Raia discussed to optimise the networks. While in early stages, this technique could give us the general purpose AI that is required to solve multiple problems.
When Microsoft bought SwiftKey it was major news for the deep learning community and it was great to hear Ben Medlock discuss the history of the company, the acquisition and generally where he thought the industry was headed. While I took significant notes on this, Sophie from the ReWork team posted a great blog post and the video of the interview covering it in detail and there’s no need for me to recreate it. However, one of the big things he did discuss that is worthy of far deeper discussion is the moral and legal agency of AI5 – I firmly believe we need ground rules regarding the power that we devolve before this becomes an issue.
After a coffee break where most of us carried on the moral discussions in smaller groups, Oriol Vinyalis of Google DeepMind gave us an overview of Generative Models. One of the interesting things to note is that Google themselves use the number of products/items they produce that use deep learning as an internal measure of its growth and is probably relatable to the growth of DL in the wider industry. Deep generative models use (mostly) unlabelled data – e.g. for worldwide news a specific language and domain are required so the data has some inherent scope. The question is, can we generate a genuine new sample from a given modality? If so, how do we evaluate this and do we even care?
There are three current trends: Generative Adversarial Networks (while there are lots of papers on this, these networks are challenging to train), VAEs (inference networks can compliment GANs), and sequence models (can predict sequences with joint probability distribution).
With language, the first step is to predict the next word given all previous words, but a more believable output would be prediction of the next word based on the whole conversation6 There are lots of great papers with examples of these that Oriol referenced: Jozefowicz et al with examples of sentences, Karpathy who created artificial code samples, Vingals et al with conditional language for images. Finally, Van den Oord et al who used wavenets to generate English sounding speech samples. All papers are well worth reading.
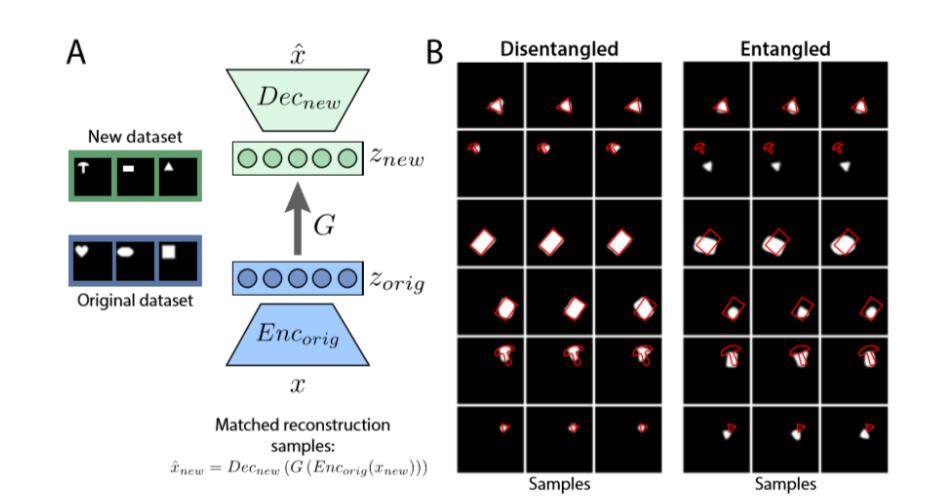
Google were well represented with their third speaker of the morning, Irina Higgins, talking about unsupervised representation learning.She gave an example of captioning fails from Karpathy and Fei-Fei where the network doesn’t show understanding of what is happening in the image. Humans can adjust easily, but networks need to be retrained – even colour changes can cause problems. So what is a good representation? Our world is structured and (most) tasks are constrained by the structure of our world There is a universal representation, but it is not simple! We need to disentangle generative factors of variations with no a priori knowledge of factors, e.g. scale vs colour: same colour in all sizes, small objects in all colours and extrapolate to large objects in unseen colours. There are lots of semi supervised approaches as well. Real world data is continuous and we need approaches that can cope with the real world. Irina and her team had used a variational auto encoder to encode and decode and then check the differences. They quantified the disentanglement of the factors to find low level items that could be used to extrapolate unknown objects. They deliberately tested the network on unseen images. The disentangled network was able to generalise, while the entangled network was not as good (although the results for the entangled network were not that bad). It was interesting to note that perfect reconstructions where not equal to good representations and the most popular data sets lack the right level of continuity. Irina’s paper on this can be found on arxiv.
Irinia and team’s results from https://arxiv.org/abs/1606.05579
Murray Shanahan from Imperial was up next discussing deep reinformcement learning, who was the advisor for the film Ex Machina. Deep reinforcement learning maximises future reward over time but requires large amounts of data and is slow at learning (can be compared to a young child). For a simulation, after hours of hyper real time learning, the network is still “dumb” – there is no high level cognition. To improve, it is necessary to exploit the causal structure of the domain (an artificial limbic system). Could it ever be possible to extract a human comprehensionable reasoning for decisions? Murray proposed joining current neural networks and symbolic AI together. Symbolic AI is currently unfashionable – the representations are determined by the engineers so the system cannot generalise. However, with a hybrid architecture the strengths of both could be utilised. A neural back end providing an unsupervised learned statistical structure and then a symbolic front end with reinforcement learning could give much more generalised power. I liked this idea – it’s similar to how our brains work: our limbic system and frontal lobes work together to provide a combination of skills. Murray tested this hypothesis on simple games with grids and random layouts. For a grid structure, the symbolic hybrid was little better than chance, while the DQN performed well. Both were poor for the random layout. However, when the systems were trained on a grid layout but tested with random, the symbolic network performed better as it learned the rules of the game rather than just statistical placements. The paper on this has recently been updated and is on arxiv. Murray finished his talk with an impassioned plea to “transcend your paradigm!” – I want this on a t-shirt 🙂
The last talk of the morning was from Miriam Redi of Bell Labs on the subjective eye of machine vision – can machines see the invisible? Traditional machine vision detected by shape. Our understanding of what is happening in an image is influenced by culture, psychology etc, and our emotional response to an image can be influenced by aesthetics as well as the subject matter. We can teach networks aesthetics, but can we add in cultural factors? By understanding where classifiers go wrong, we can fix them – Miriam gave a great example here of how beauty algorithms for images can be biased towards caucasions due to training data, and this can be resolved with better range of data with multiple ethnicities. For creativity, can we determine something new? By taking vine videos (6 second limit to these files simplified the problem) they were able to identify videos with visual novelty, good colours etc. In this way, they could begin to classify whether something was new and whether it was potentially valuable. However, the cultural aspect varies wildly by city – the images that evoke emotion differ. A second project looking at Flickr images showed this variation. With 24 keywords over 12 languages they determined that there was some multi lingual clustering, but also a lot of monolingual clusters in how images were percieved. Chinese sentiment was the most different to the other languages, but this was the only non-EU language studied. The aim was to predict the sentiment response to an image by language to surface beautiful images thqat may otherwise have been hidden. Miriam and her team created an AlexNet based model to determine this with good results in the languages studied, but some languages are poorly represented and this leads back to the data availability problem with which we started the morning.
Some of these talks are now available on the Rework YouTube channel and I will add my notes on the rest of the talks soon.
Most of the audience weren’t aware of this early pioneer, and I wonder how many people have been lost in history just because it was the improvement on the design that is remembered and made the household name… ↩
In Europe, our data laws prevent this use without explicit opt in consent ↩
My own work on artificial neurons started back in 1999 and I recall how hard it was to get interest and funding back then. ↩
Something I discuss in detail in one of my professional blog posts http://www.marketingtechnews.net/news/2016/oct/28/artificial-intelligence-data-and-legal-debate-what-marketers-need-know-now/ ↩
This would required interpretation of meaning of all sides of the conversation, not just the artificial “speaker”. ↩
Dr Janet is a Molecular Biochemistry graduate from Oxford University with a doctorate in Computational Neuroscience from Sussex. I’m currently studying for a third degree in Mathematics with Open University.
During the day, and sometimes out of hours, I work as a Chief Science Officer. You can read all about that on my LinkedIn page.
View all posts by janet
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.