Chief Science Officers have a lot to live up to… (image credit Wikipedia)
I’ve been with my current company for 9 months as Chief Information Officer and had responsibility for everything technical from production systems down to ensuring the phone systems worked and everything in between. The only technical responsibilities not under me was the actual development and QA of our products. CIO is a thankless role – when everything is going right, questions are raised over the size of the team and the need to replace servers and budget for new projects. When something breaks, for whatever reason, you are the focus of the negativity until it is resolved. The past 9 months have been a rollercoaster of business needs, including many sleepless nights. However, I can look back on this knowing that when I do finally get around to writing about my experiences as a woman in IT I will have a lot of fun stories for the CIO chapter1. While I didn’t have the opportunity to finish off as many of the improvement projects as I would have liked, I’ve built up a fantastic team and know that they’ll continue to do a fantastic job going forward.
This week, I finished the handover of all my old responsibilities and started the role I was actually hired for back in 2015, but didn’t start with because the business needed a strong pair of hands elsewhere. I am now Chief Science Officer and have a new team of Computer Vision researchers and am taking over all of the data science and machine learning activities worldwide. I’ve been given a remit of thought leadership with the team, so I’ll be attending (and speaking at) conferences, writing blog posts, publishing papers and let’s not forget that I’ll be neck deep in the research myself, leading a team of academics within a corporate environment on computer science research.
While I won’t be able to talk about what we’re doing until we’re ready to make it public, I will be blogging about the kit we’re using and some generic machine learning issues, as well as interesting papers as and when I find them.
It’s going to be a pretty exciting time – there are several cool projects that we’ve started and I’ve given myself some harsh deadlines so that we can have some results ready for a conference…
Please do not park bicycles against these railings as they may be removed – the railings or the bikes? Understanding the meaning is easy for us, harder for machines
Last year I wrote a post on whether machines could ever think1. Recently, in addition to all the general chatbot competitions, there has been a new type of test for deeper contextual understanding rather than the dumb and obvious meanings of words. English2 has a rich variety of meanings of words with the primary as the most common and then secondary and tertiary meanings further down in the dictionary. It’s probably been a while since you last sat down and read a dictionary, or even used an online one other than to find a synonym, antonym or check your spelling3 but as humans we rely mostly on our vocabulary and context that we’ve picked up from education and experience.
This is a summary of day 2 of ReWork Deep Learning summit 2016 that took place in Boston, May 12-13th. If you want to read the summary of day 1 then you can read my notes here. Continue reading Rework DL Boston 2016 – Day 2
Last year, I blogged about the rework Deep Learning conference in Boston and, being here for the second year in a row, I thought I’d do the same. Here’s the summary of day 1.
The day started with a great intro from Jana Eggers with a positive message about nurturing this AI baby that is being created rather than the doomsday scenario that is regularly spouted. We are a collaborative discipline of academia and industry and we can focus on how we use this for good. Continue reading ReWork DL Boston 2016 – Day 1
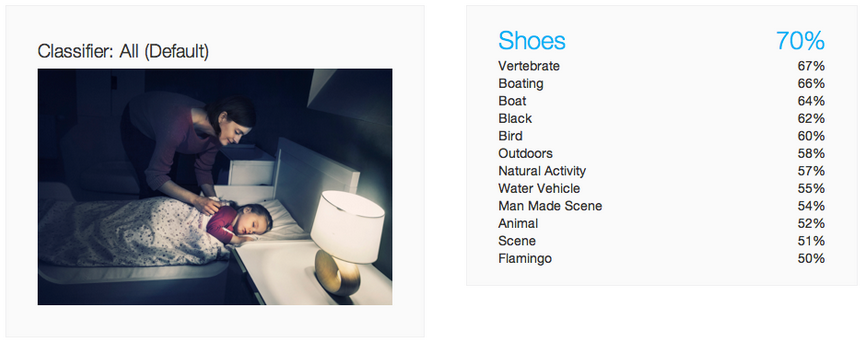
Result from IBM watson using images supplied by Kaptur
There’s a lot of money, time and brain power going in to various machine learning techniques to take the aggravation out of manually tagging images so that they appear in searches and can be categorised effectively. However, we are strangely fault-intolerant of machines when they get it wrong – too many “unknowns” and we’re less likely to use the services but a couple of bad predictions and we’re aghast about how bad the solution is.
With a lot of the big players coming out with image categorisers, there is the question as whether it’s really worth anyone building their own when you can pay a nominal fee to use the API of an existing system. The only way to really know is to see how well these systems do “in the wild” – sure they have high precision and recall on the test sets, but when an actual user uploads and image and frowns at the result, something isn’t right. Continue reading AI for image recognition – still a way to go
A few days ago, researchers from Facebook published a paper on a deep learning technique to create “natural images”, with the result being that human subjects were convinced 40% of the time that they were looking at a real image rather than an automatically generated one. When I saw the tweet linking this, one of the comments1 indicated that you’d “need a PhD to understand” the paper, and thus make any use of the code Facebook may release.
I’ve always been a big believer in knowledge being accessible both from being freely available (as their paper is) and also that any individual who wants to understand the concepts presented should be able to, even if they don’t have extensive training in that specialism. So, as someone who does have a PhD and who is in the deep learning space, challenge accepted and here I’ll discuss what Facebook have done in a way that doesn’t require advanced degrees, but rather just a healthy interest in the field2. Continue reading Facebook’s latest deep learning research
At the ReworkDL conference in Boston last month I listened to a fantastic presentation by Ryan Adams of Whetlab on how they’d created a business to add some science to the art of tuning deep learning engines. I signed up to participate to their closed beta and came back to the UK very excited to use their system once I’d got my architecture in place. Yesterday they announced that they had signed a deal with Twitter and the beta would be closed. I was delighted for the team – the business side of me is always happy when a start-up is successful enough to get attention of a big corporate, although I was personally gutted as it means I won’t be able to make use of their software to improve my own project.
The first session kicked off with Kevin O’Brian from GreatHorn. There are 3 major problems facing the infosec community at the moment:
Modern infrastructure is far more complex than it used to be – we are using AWS, Azure as extensions of our physical networks and spaces such as GitHub as code repositories and Docker for automation. It is very difficult for any IT professional to keep up with all of the potential vulnerabilities and ensure that everything is secure.
(Security) Technical debt – there is too much to monitor/fix even if business released the time and funds to address it.
Shortfall in skilled people – there is a 1.5 million shortage in infosec people – this isn’t going to be resolved quickly.
So, day one of the ReWork Deep Learning Summit Boston 2015 is over. A lot of interesting talks and demonstrations all round. All talks were recorded so I will update this post as they become available with the links to wherever the recordings are posted – I know I’ll be rewatching them.
Following a brief introduction the day kicked off with a presentation from Christian Szegedy of Google looking at the deep learning they had set up to analyse YouTube videos. They’d taken the traditional networks used in Google and made them smaller, discovering that an architecture with several layers of small networks was more computationally efficient that larger ones, with a 5 level (inception-5) most efficient. Several papers were referenced, which I’ll need to look up later, but the results looked interesting.
If you’ve been following this blog you’ll know that I’ve started a new role that requires me to build a deep learning system and I’ve been catching up on the 10+ years of research since I completed my PhD. With a background in computing and mathematics I jumped straight in to what I thought would be skimming through the literature. I soon realised that it would be better all round to jump back to first principles rather than be constrained with the methods I had learned over a decade ago.
So, I found a lot of universities who had put their machine learning courses online and have decided to work through what’s out there as if I was an undergraduate and then use my experience to build on top of that. I don’t want to miss an advantage because I wasn’t aware of it.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.