There’s a lot of money, time and brain power going in to various machine learning techniques to take the aggravation out of manually tagging images so that they appear in searches and can be categorised effectively. However, we are strangely fault-intolerant of machines when they get it wrong – too many “unknowns” and we’re less likely to use the services but a couple of bad predictions and we’re aghast about how bad the solution is.
With a lot of the big players coming out with image categorisers, there is the question as whether it’s really worth anyone building their own when you can pay a nominal fee to use the API of an existing system. The only way to really know is to see how well these systems do “in the wild” – sure they have high precision and recall on the test sets, but when an actual user uploads and image and frowns at the result, something isn’t right.
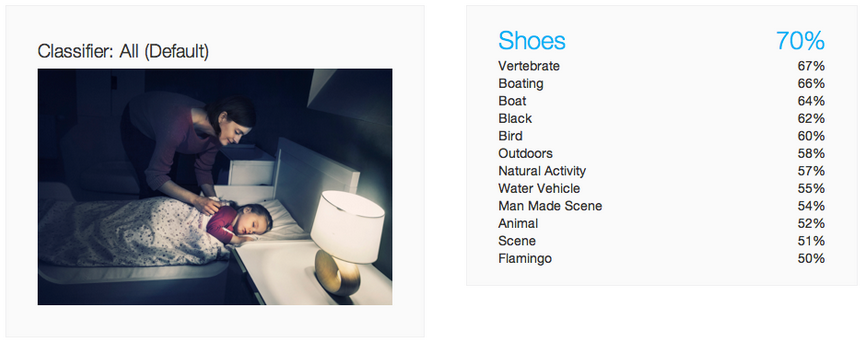
Kaptur posted some test results1 a few days ago where they had tried 6 random images against the top 5 engines: IBM Watson, Clarifai, Orbeus, Flickr, Imagga. The results were worse than I had expected for systems that had gathered so many people and put so much investment into developing. Rather than regurgitate their results, I suggest you read the post for yourself, although it does highlight two particular problems about AI systems.
Firstly, a lot of them “cheat”. I use the quotes here because because we also cheat when it comes to visual recognition: we use context to help us distinguish items 2. Many of these systems suggest related keywords even if the item they are matching isn’t obvious in the image3. When you don’t dig too deeply, suggesting related predictions can give surprising accuracy in a lot of cases, but when you get an error, they can be really quite shocking.
Secondly, they only know what they’re told. If you train an engine on celebrity recognition, then you’ll get good results on celebrities, but if you throw a stock image of non-celebrities or a landscape at these engines then you’ll get poor results. Similarly, you train on objects and you won’t get recognition for people we’d find obvious.
Flickr has gone far too conservative in its approach, only offering the basic of generalised tags, which are no real use – you still have to add all the relevant words – this is a case of too many unknowns. Similarly, the others are not as accurate as would be needed to trust them without checking all the predictions, in which case why not just tag the images from a tag cloud yourself?
Specialist image recognition is working well – animal classification, food matching4 – but this goal of generic “matching like a human” still seems just out of reach and I feel that we’re waiting on the brink of the next big innovation in this field as the gradual evolutions we’ve had since deep learning is beginning to falter.
- http://kaptur.co/visual-content-recognition-a-test-drive/ ↩
- There was a great talk on this at ReWork DL by Prof Olivia, MIT: Humans perceive places first, then objects within them, which is why sometimes we know something is wrong before we are consciously aware of what. ↩
- For example, the 3rd image of the couple by water generated results of boat by Watson, and the fifth image Orbeus suggests this is a party because there is a group of people. ↩
- Assuming you keep within the narrow parameters of the training. ↩