Last week, I attended the Re Work Explainable AI mini summit. I am really loving so many great speakers being accessible online, particularly in a three to four hour format, which makes it easy to fit in around work commitments better than an in person summit – had it not been online I would have missed out on some great speakers.
Explainability is something I’ve been really focussing on recently. While it’s always been important, my frustration has been in research focussing on tools for machine learning engineers and not on clear explanations for the general public – the very people using, and being affected by, the systems we build. I was keen to attend this summit in particular as a refresh of where we were in terms of current best practise.
Many current explainability solutions are flawed. When we are seeking to “explain” what is going on in models we look at e.g. SHAP values to show the contribution of features to the overall predictions. We make simplifications when the number of features gets too big for us to justify the time and effort involved. Our output? A table of numbers which we might blur into a visualisation. We write a paper, pat ourselves on the back for a well explained model and move on.
The general public are not so lucky. The majority of people affected by or using our systems are not mathematicians and these results without further explanation are not tangible. We have a duty to ensure that people understand why they are getting the results they do, whether this is for regulatory reasons or a simple recommendation. This means that any explainability needs to be accessible for the lay-person, in plain English, that’s more informative that Baldrick’s attempt to classify a dog…
E: What about `D’?
B: I’m quite pleased with `dog’.
E: Yes, and your definition of `dog’ is…?
B: “Not a cat.”
Blackadder the Third, Ink and Incapability, very similar to the over-simplified explanations we have for classification tasks 😉
The summit started with an introduction by Anusha Sethuraman of Fiddler, who also introduced each speaker and moderated the question sessions. The first session was Tristan Ferne from BBC’s R&D team. Starting with a clear “We should all be explaining AI and machine learning better” he showed that it is ubiquitous, opaque, can easily be deployed without notification and can go wrong in unusual and unpredictable ways.
Tristan argued that we need to focus on the purpose of the AI and the user needs – this will be different from system to system. Sometimes “what” is more important than “why”. He showed a garden bird identifier that had been built by his team. In these sorts of situations the user wants to know what has impacted the classification and some comfort around the uncertainty. The identifier had heat maps to show the important features that led to the classification and also offered alternatives for near matches. “Most likely to be …” and ” it could be” gave the user comfort that that even if the main prediction is wrong, the system is still performing well with the alternatives.
The system also included a visual representation of the data used to train the system, showing bias towards ducks, sparrows and starlings. Tristan highlighted a paper released a few days earlier covering this topic: What Do We Want From Explainable Artificial Intelligence (XAI)? — A Stakeholder Perspective on XAI and a Conceptual Model Guiding Interdisciplinary XAI Research1. He ended with underlining that you need to understand why you are trying to explain a system and to whom, and this was key to decide where and how to do the explanation.
Next was Rishabh Mehrota from Spotify. With 60 million tracks, it’s practically impossible for users to find new content other than what they already know. Spotify offers several ways of doing this in addition to a raw “search”. Their radio feature gives sequential predictions, there are mood hubs with common types of music, and recommendations based on listening patterns. They focus on “recsplanations” (recommended explanations) to help the user understand what they are seeing. He highlighted a great paper on this that he had co-authored a few years ago: Explore, Exploit, Explain: Personalising Explainable Recommendations with Bandits. Basically are you exploiting what you know (you like rock music, so here is more rock music), exploring something related (you like this artist so you might like these artists as well), and then explaining (you listen to this sort of music on Fridays so you might want more of that today).

Rather than go into the details of these different “shelves”, Rishabh talked about some of the science they’d done in understanding whether these explanations helped users and if there were any preferences as to the type of explanation. They discovered that users do react differently based on the explanation and further more that detailed explanations give more reaction, but this didn’t work for “mood”, which might be due to its breadth as a category. The difficulty here is that there are multiple objectives in the model – if the user does not like the recommendation it is difficult to ascribe that to a specific objective.
Spotify use “human in the loop” AI and enlist a lot of editorial help to categorise the music and create relations, which makes clear English explainability easy as it is built in to the data. The explanations have to be relatable otherwise the user does not connect.
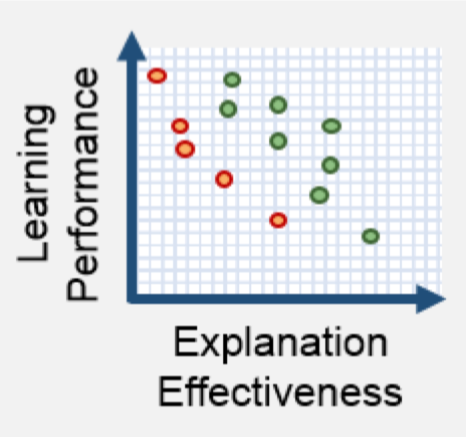
The third talk was from Cynthia Rudin from Duke University with a somewhat provocative talk that explainable AI perpetuates the problems we have and instead for high stakes decisions we should use interpretable models instead. One of the first things she did was reference a report from DARPA XAI in 2016 that showed a graph that explainability had an inverse relationship with performance. She picked this apart completely, but the key point is that this was a graph to support an assumption (or possibly a single set of experiments) rather than a general concept, but has been taken as a “truth” by the AI community since. A good reminder to look at the original data for any conclusions and if there is no data then assume it’s made up… even in Data Science!
Explainable ML is post hoc explanations for opaque models to justify the results. Interpretable ML is embedded in the design and was there as a field first! Part of this is down to the data and the other is the choice of model. Sparse models can perform similarly to neural network models if properly designed. For discrete variable data (each attribute makes sense on its own, like tabular information) sparse models are easily interpretable. Where you have raw data (sound or images for example where a single second or pixel does not make sense in isolation, it is more difficult but not impossible.
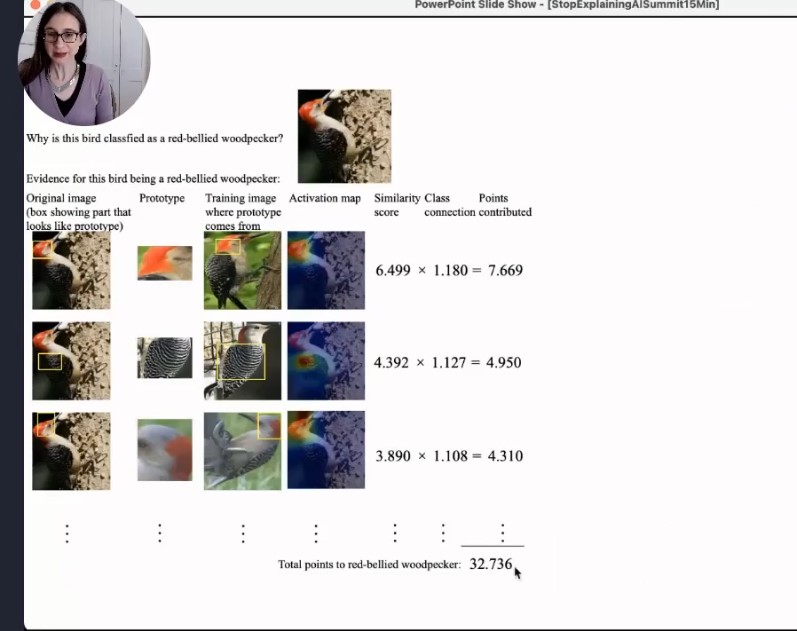
Cynthia had another bird demo2 and showed a demo of “this bit looks like that” which was very simple for an end user to understand the concepts and was covered in a paper from her lab.
She then discussed how interpretable concepts could be applied to complex neural networks to achieve explainability. There’s no clear concept for a node in the layers in the network – the concepts are entangled. The concept vector could be the same for two distinct concepts, making it impossible to use for interpretability directly. However, Cynthia’s lab released a paper in 2020 showing how their CW layer could replace a batch normalisation layer to disentangle latent space and put concepts along the axes while not hurting performance. Adding this type of layer can make the opaque network become translucent and aid interpretability3. Code for the techniques she presented are on her lab website.
For an opposite view on this, Cassie Kozyrkov argues that you can’t have both understanding and performance with a clear analogy about two spacecraft: one you know how it works and the other is thoroughly tested – which one do you choose? (video and Hackernoon article “Explainable AI won’t deliver. Here’s why.”, which is more verbose). She uses explainability and interpretability interchangeably unlike Cynthia Rudin. My problem with this is that the argument is reduced to an either/or – however you can test explainable (or interpretable) systems thoroughly… and there is no excuse for not testing! But also, when Cassie goes on to use the example that you don’t ask your colleagues why they chose tea over coffee… of course not, (unless it’s an unusual behaviour) but presenting a legal case or a medical diagnosis we don’t just step back satisfied on a police officer or doctor’s “gut instinct” – we need facts. We need explainability. This is important. In high stakes decisions you need to know how as well as why. While I completely agree with Cassie Kozyrkov that you need to look at the business need, I think it’s potentially dangerous to dissuade people in the industry, or even the lay person, from wanting some justification. We’ve seen many examples where the testing is not up to scratch, and most people do not have the understanding of the statistics to question test results, particularly when looking at percentages. The two are needed in combination.
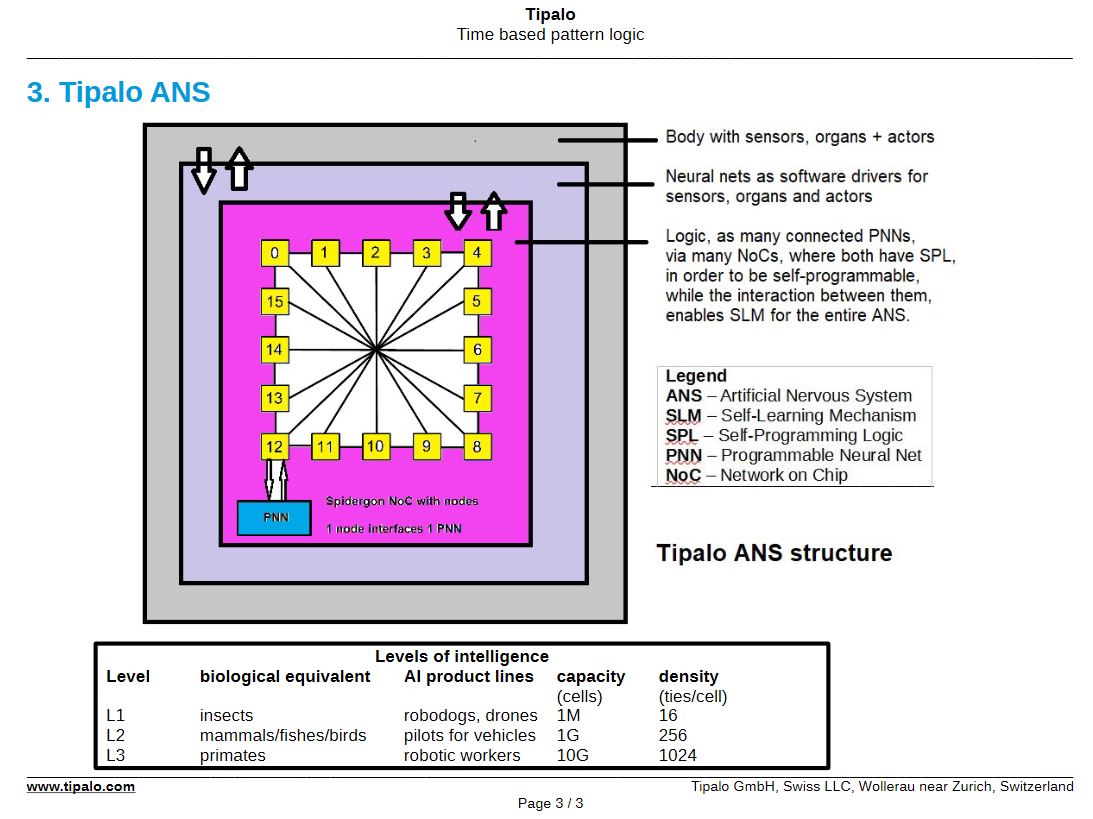
Next up was Walter Crismareanu from Tipalo. His talk seemed slightly out of place in the summit as he wasn’t presenting anything on explainability as such, but instead a different way of designing neural nets, by using logical subgroups. I’ve spoken myself previously on the differences between CNNs and biological neurons and how hard it is to assess intelligence outside of our own experience of it. I was slightly frustrated by the lack of detail here. While I understand that Tipalo want to keep their IP secret, he was making big claims about self training network clusters. When asked how they were training these networks, he suggested they weren’t being trained. Possibly something lost in translation, and I assumed by his statement that you “can’t have intelligence without a body” (sensory inputs) that they must be putting the networks in some sort of body in an environment… but it would have been nice to see this, or a video, or any sort of results. Their website does give slightly more detail than presented at the conference and I will watch this company with interest.
Rachel Alexander from Omina Technologies presented sentiments that really echo my own – explanations have been made primarily for the teams creating models and not the end users. She was looking at this from the needs of the medical industry where trust and explanations are critical. She was keen to stress that AI is for everyone, not just the happy few, and also made the distinction between explainability (why the decision was made) and interpretability (how the decision was made).
The type of information will depend on the use case. For preventable medicine, interpretability is key – models have to include this for the medical professionals and general public to trust the results. For other use cases, e.g. number of people who might be admitted, explainable models should be sufficient. SHAP values alone make models translucent, not transparent!
I had to take a break during the roundtable sessions, but rejoined in time for the final panel session with Mary Reagan (Fiddler), Merve Hickok (AIEthicist), Sara Hooker (Google Brain), and Narine Kokhlikayan (Facebook).
The panellists were mostly in agreement and discussed and extended the key points that had been raised in the preceding talks. As an industry, we need to build in interpretability as this makes better models. These tools need to be easy to use for everyone. Without transparency and accountability, we will continue to see live models with issues that become apparent only after they have done harm.
Explainability and interpretability needs to be proactive and not reactive. While there are some challenges, many of these are engineering issues and not fundamental to the techniques.
I must admit, I tend to use explainability to include interpretability because the end user wants an explanation and whether this is “how” or “why” depends on context. You need to deeply understand how your models are going to be used (the business problem) and the needs of the end user before you start creating something and then adding the explainability as an afterthought.
- Added to my list of things to read 🙂 ↩
- I guess irises are soooo last decade 😉 ↩
- She co-authored another paper in 2019 on Rashomon curves to help investigate models for simplicity vs accuracy ↩