One of the things that I find I have to teach data scientists and ML researchers almost universally is understanding how to test their own code. Too often it’s all about testing the results and not enough about the code. I’ve been saying for a while that a lack of proper testing can trip you up and recently we saw a paper that rippled through academia about a “bug” in some code that everyone used…
A Code Glitch May Have Caused Errors In More Than 100 Published Studies
https://www.vice.com/en_us/article/zmjwda/a-code-glitch-may-have-caused-errors-in-more-than-100-published-studies
The short version of this is that back in 2014, a python protocol was released for calculating molecule structure through NMR shifts1 and many other labs have been using this script over the past 5 years.
Recently, a lab in Honalulu 2 discovered that when they used the code on different operating systems they got different results.

You don’t need to understand the chemistry or the mathematics behind this to realise there is a problem here. Furthermore this was raised as an issue in 2014 and closed as “not a bug”…
That vice article about a code glitch causing errors in 100 published studies? It's because Python ignored my bug report 5 years ago and didn't change glob.glob https://t.co/3oAX4POKlE #reproducibility
— David JONES (@drjtwit) October 15, 2019
Technically it isn’t a bug as such, it’s just using the implementation of code in the underlying operating system and leaving the option for the user to sort results themselves, although the closing of the bug report does agree that this isn’t explicit in the documentation… While it’s great that this was found and a fix to the calculation code (not the underlying issue) was released 5 years after it was reported, what is important is that we stop assuming that everything we use in our development is perfect.
Part of my talk in 2018 at Minds Mastering Machines made the point that whenever you devolve responsibility for some code to someone else, whether that’s a commercial library or something open source, you are giving up control of how that piece of code works. Portability of code, as we have with Python, does not mean consistency. With each abstraction from the operating system, you add a level where change can impact the final result. People will find and log these inconsistencies, but even if they do provide warnings these are often ignored and it’s a practical impossibility to keep on top of all the bugs for every single dependency we use.
So how to get around this?
The quickest fix is to ensure that you use virtual environments with clear versioning in your requirements.txt. This will ensure consistency. If you release code, release a container for reproducibility, but at the very least make it clear the versions you have used, including the version of the underlying operating system.
However, the thing you should do, the thing you should be doing now, is testing your code. If you are expecting results sorted from a third party library then assert this with test data. Anytime you are assuming a result test it. Run these tests whenever you upgrade a library or your OS. Run these test as part of your builds. Don’t just assume that things are perfect.

One of the great fallacies of life is that if a few results are proven true then we devolve a level of trust to the source of those results. It’s easy to do an ad hoc test without even realising we are doing it when we first learn to use a few functions (unless of course you’ve blindly pasted some code from Stack OverFlow because it fixed someone else’s problem3. What most people don’t do is save these steps as tests to check everything does what it should when you move from Python 2.7 to 3.4, or Tensorflow 1.14 to 2, or even NumPy 1.14 to 1.16. Versions change for a reason. Not everything is backwardly compatible and sometimes things change how they return results5.
One thing that’s great in Python is that unit testing is really easy. There’s even a library6 that is subtly called “unittest”. With this you can mock data, call the functions in your code and check whether the returned results match what you expect. Here’s a trivial example:
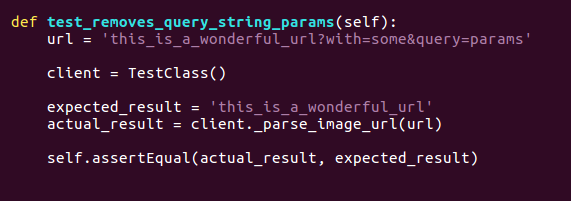
Some things to note. Firstly the test is named for what is does so when you run the tests you can see exactly which failed. We have an input value url and we’ve defined the test class we’re going to pass it to. We know what we expect, we call the appropriate function and then check that they expected matches actual.
If you are expecting that a function will return the largest (or smallest) value then you can check this pretty easily. You should write test for all critical parts of your code at the very least. Then you shouldn’t be caught out by the differences that impacted people using the Willoughby-Hoye scripts.
Further, you shouldn’t leave running these tests to memory. Add it to your continuous integration and deployment process. On every commit to source code control, have something that checkouts out the code, builds it and tests it before letting you know if it’s ready to deploy. We use codeship for this7 and we all want the green tick against our commits that says it’s good to go. Any push to GitHub and our containers are built with the specified versions and a suite of tests run from checking PEP8 compliance of the code through to ensuring that each function returns what’s expected. Naturally when the tests fail we grumble and put it right, but it means that we put it right before it becomes a problem and affects any results.
You should too. Testing is everyone’s responsibility.
- Patrick H. Willoughby, Matthew J. Jansma, Thomas R. Hoye, Nat. Protoc.2014, 9, 643–660. https://doi.org/10.1038/nprot.2014.042 ↩
- Characterization of Leptazolines A–D, Polar Oxazolines from the Cyanobacterium Leptolyngbya sp., Reveals a Glitch with the “Willoughby–Hoye” Scripts for Calculating NMR Chemical Shifts, Jayanti Bhandari Neupane, Ram P. Neupane, Yuheng Luo, Wesley Y. Yoshida, Rui Sun, Philip G. Williams, Org. Lett.2019.
https://doi.org/10.1021/acs.orglett.9b03216 ↩ - Don’t get me started on this – I have to explicitly tell people not to do this and check they understand code before they run it on their machines… I’ve had employees before who’ve trashed their machines because they were following steps they didn’t understand…. sighs ↩
- Which you really should 😉 ↩
- This would probably be a good time to go off onto a rambling anecdote about the C library I found that redefined False as True at the beginning and my attempts to “fix” it, but I’ll save that one for my book! ↩
- I appreciate the irony in this but any issues will show up if you code the tests properly. ↩
- I’ll happily do a further post on this if there’s interest. ↩