This week I was due to be sat in a large hall with about 200 other Open University students taking my exam for module M347, the last of the modules for the BSc in Mathematics I started for “fun“1. As with students in traditional universities, March 2020 gave a lot of uncertainty2. While some modules were switched to be coursework based assessment, mine was confirmed to be a remote exam with the originally planned exam paper. The paper would be accessible as a PDF on the day of the exam and then submitted in two parts: a multiple choice computer marked section and then a human marked second section. We would not be time limited (other than by the 24 hours in the day!) So how did I feel about this and how did it go?
Continue reading My first remote exam experience
How to be a Rockstar Neural Network Developer
There’s a trend in job descriptions that the company may be looking for “Data Science Unicorns”, “Python Ninjas”, “Rockstar developers”, or more recently the dreaded “10x developer”. When companies ask this, it either means that they’re not sure what they need but they want someone who can do the work of a team or that they are deliberately targeting people who describe themselves in this way. A couple of years ago this got silly with “Rockstar” to the point that many less reputable recruitment agencies were over using the term, inspiring this tweet:
Many of us in the community saw this and smiled. One man went further. Dylan Beattie created Rockstar and it has a community of enthusiasts who are supporting the language with interpreters and transpilers.
While on lockdown I’ve been watching a lot of recordings from conferences earlier in the year that I didn’t have time to attend. One of these was NDC London, where Dylan was giving the closing session on the Art of Code. It’s well worth an hour of your time and he introduces Rockstar through the ubiquitous FizzBuzz coding challenge.
After watching this I asked the question to myself, could I write a (simple) neuron based machine learning application in Rockstar and call myself a “Rockstar Neural Network” developer?
Continue reading How to be a Rockstar Neural Network DeveloperM347 – Mathematical Statistics – preparing for the exam in the “new normal”
Today I submitted the last assessment ahead of the exam for my tutor to mark in my Mathematical Statistics module. For once, I’m actually on track with my study but it’s not been without difficulty. If you’ve been following my OU journey then you’ll know I work full time and have a family, so dedicated study time can often be a low priority. Up until the second week of March this year1 I had a reasonable routine: I’d spend the two hours I commute Monday to Friday going through the course materials and then this extra maths wouldn’t impact work or home life.
Continue reading M347 – Mathematical Statistics – preparing for the exam in the “new normal”Remote Data Science – Interview
Last week I was interviewed by Keith Robinson of Ammonite Data, with a topic of managing data science teams remotely and all the challenges this brings. We had a much more wide ranging conversation where I looked at challenges of communication and even the impact on models that the current extraordinary events will have.
I hope you find these enjoyable and helpful.
Review: Lego Ideas International Space Station
For the past two weeks I have, like most people, been working from home. Doing fun stuff just for yourself during this time can be incredibly important, and with this in mind I’ve started going through some of the Lego and other building kits I’ve got and just not had time to open. The first of these that I’ve tackled is this years Ideas (fan-designed) Lego set the international space station.

Data Science Courses – the missing skills you need
One of the things that I have been complaining about with many of the data science masters courses is that they are missing a lot of the basic skills that are essential for you to be able to be effective in a business situation. It’s one of the things I was going to talk about at the Women in AI event that was postponed this week and I’m more than happy to work with universities who want to help build a course1. That said, some universities are realising this is missing and adding it as optional courses.
Continue reading Data Science Courses – the missing skills you needA diagnostic tale of docker

If you’ve been to any of my technical talks over the past year or so then you’ll know I’m a huge advocate for running AI models as api services within docker containers and using services like cloud formation to give scalability. One of the issues with this is that when you get problems in production they can be difficult to trace. Methodical diagnostics of code rather than data is a skill that is not that common in the AI community and something that comes with experience. Here’s a breakdown of one of these types of problems, the diagnostics to find the cause and the eventual fix, all of which you’re going to need to know if you want to use these types of services.
Read more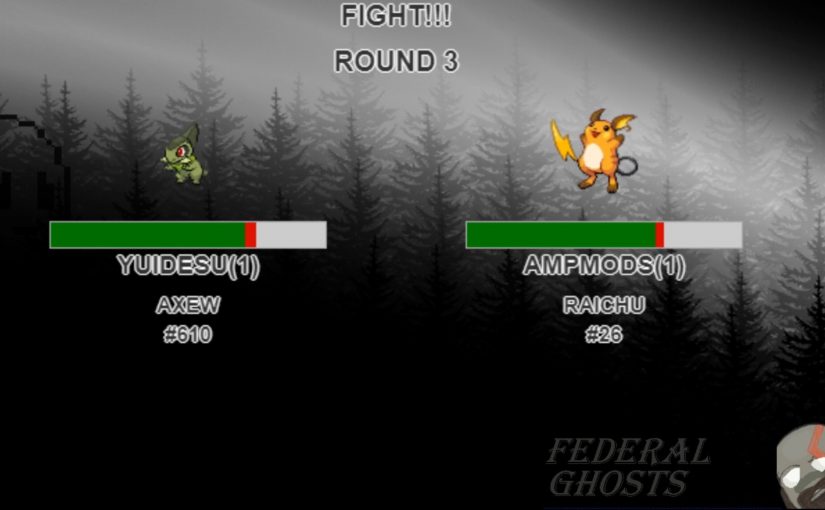
Mathematics of player levels in game development
My husband is a game developer and my contributions are usually of the sort where I look at what he’s done and say “hey wouldn’t it be great if it did this”. While these are usually positive ideas, they’re mostly a pain to code in. Today however, I was able to contribute some of my maths knowledge to help balance out one of his games.
Using an open api, he’d written a simple pokemon battle game to be used on twitch by one of our favourite streamers, FederalGhosts, and needed a way of determining player level based on the number of wins, and the number of wins required to reach the next level without recursion. While this post is specifically about the win to level relationship, you could use any progression statistic by applying scaling. Here we want to determine:
- Number of wins (w) required for a given level (l)
- The current player level (pl) given a number of wins (pw)
- Wins remaining to the next level (wr) for a player based on current wins (pw)
Let’s take a look at a few ways of doing this. Each section below has the equations and code examples in python1. Assume all code samples have the following at the top:
import math
database = [
{"name": "player1", "wins": 5},
{"name": "player2", "wins": 15},
{"name": "player3", "wins": 25}
]Data: access and ethics
Last week I attended two events back to back discussing all things data, but from different angles. The first, Open Data, hosted by the Economist was an event looking at how businesses want to use data and the ethical (legal) means that they can acquire it. The second was a round table discussion of practitioners that I chaired hosted by Ammonite Data, where we mainly focussed on the need for compliance and balancing protection of personal data with the access that our companies need in order to do business effectively.
We’re in a world driven by data. If you don’t have data then you can’t compete. While individuals are getting more protective over their data and understanding its value, businesses are increasingly wanting access to more and more – at what point does legitimate interest or consumer need cross the line?
Continue reading Data: access and ethicsHow much maths do you really need for data science?
My LinkedIn news feed was lit up last week by a medium post from Dario Radečić originally posted in December 2019 discussing how much maths is really needed for a job in data science. He starts with berating the answers from the Quora posts by the PhD braniacs who demand you know everything… While the article is fairly light hearted and is probably more an encouragement piece to anyone currently studying or trying to get that first job in data science, I felt that, as someone who hires data scientists1, I could add some substance from the other side.
Continue reading How much maths do you really need for data science?