
If you’ve been to any of my technical talks over the past year or so then you’ll know I’m a huge advocate for running AI models as api services within docker containers and using services like cloud formation to give scalability. One of the issues with this is that when you get problems in production they can be difficult to trace. Methodical diagnostics of code rather than data is a skill that is not that common in the AI community and something that comes with experience. Here’s a breakdown of one of these types of problems, the diagnostics to find the cause and the eventual fix, all of which you’re going to need to know if you want to use these types of services.
Background
We develop models locally and then have an automated script that packages them into docker containers. This script ensures that all our models have common code and we can update in one place and run automated tests every time we update a model or change a library1. As such very little is different code wise between our different model containers. We have a staging area where we have a single instance of each model and a production area with multiple copies for resiliency. This is all done with cloud formation on AWS. None of the containers on AWS are directly accessible – we have to be pretty confident when we release a container that it’s working, although logging and reporting to Sentry help us catch any odd behaviour, which is usually pretty benign. Usually, we are. This week we had an outlier, which was a pretty fun thing2 to investigate.
The issue
After pushing a lot more data through our models, we found some edge cases that needed fixing that were returning errors to sentry. Not a big issue and perfectly normal when increasing the amount of data by several orders of magnitude. These were all pretty easy fixes. Then we noticed that one of the models was constantly not responding when it was called. Errors were:
- name or service not known
- no route to host
- connection timed out
These were all going to sentry, which was showing a lot of this occurring3. My first thought was that we’d missed this from our cloud formation template yaml, but it was trivial to see that this was not the case and inspection of the set up within AWS control panel showed that the container was up and running. However, as I watched I could see that the container was crashing about every 20 – 40 minutes and rebooting itself (thanks to cloud formation).
Now intermittent errors can be some of the most annoying to track down as you need a reliable way to replicate them.
The first thing was to look at the logs:

Not overly helpful – everything is working fine and then there’s a segmentation fault. There were several of these logs and they all ended the same way.
Checking the history, I could see that the amount of data processed before the crash varied, with a minimum of 25 to several hundred. I didn’t do this particularly scientifically – just enough to verify that this was not a fixed time or number.
So we had a segmentation fault that was occurring intermittently, but frequently, on our live set up that we had not seen in either development or UAT. We had no way of accessing the containers on live.
Recreation
It’s natural at this point to push new versions with huge amounts of debug into live or want to go straight to google or stack overflow. Don’t. I’ve had many situations where even adding extra logging has masked an issue4. Before you do anything else ask yourself what has changed and recreate it locally.
In this case, neither the surrounding code not the model had changed, but what had changed was the load – we were putting a lot more data through the system. The first thing I did was attempt to recreate that.
We have a test harness so I ran that with tens of thousands of data points. Nothing. The next difference was that the live system was running threaded while the development version was unthreaded. I made this change and rebuilt the container locally then reran the test harness. Still nothing. The final difference was that in the live environment there were multiple calls in parallel. I reran the test harness but put it in the background and could quickly run it again (on Linux) with a quick up arrow and enter.
(venv)xps:~/git/model-docker$ python3 api_tester.py &
[1] 29013
(venv)xps:~/git/model-docker$I ramped up the number of tests running and when I got to 10 I got the seg fault. To check this wasn’t a fluke, I stopped everything, reset the container and tried again, immediately running 10 copies of the test harness and the error triggered. Great. This is the starting point. If you cannot recreate the error locally then you cannot prove that you have fixed it. While there may be occasions where this recreation is impossible, they are usually few and far between. With any issue, make sure you can recreate it and then ask what had changed. I could recreate it and the only change was threading and volume.
Now, even though I could recreate the issue I still wasn’t able to get any more information without changes: adding the fault handler and running using gdb. This added a layer of complexity in that the base container image we used was the one that ran the code and set up the api features so I needed to investigate in two containers simultaneously.
To achieve this, I had 5 terminals set up5:
- Virtual environment with the test harness
- Build and run for the erroring model docker container
- Build and run for the base docker container
- Base container code editor
- Model container code editor
Diagnostics
All of our code is set up to run the entry point into the API and listen on a port, remove this and the container exits. When diagnosing, you want to change as little as possible in case you stop the issue happening without knowing why – you may mask the issue rather than solving it. This is one of the reasons why you shouldn’t just dive in and update libraries… who knows what else might break when deprecated functions are suddenly removed. So the first thing was a little script that could permanently run while I could control debug.
import time
while(1):
time.sleep(1)I then modified the Dockerfile for our base container to run this new script on startup:
CMD /etc/init.d/xfvb start && export DISPLAY:1 && python3 run2.pyThen I could build the base container and when that had finished the model container, which I brought up normally. I then investigated the container with:
docker exec -it aimodel_ai-model_1 bashOnce inside the container in the bash shell I manually started the application:
python3 run.pyThis started up the API and bound it to the correct ports. I then ran the test harness 10 times to verify I could still recreate the issue. I could. When the fault happened, the container still looked like it was running in the terminal from which I’d done the `docker-compose up` so I exited that as well.
Now to start the diagnosis. I brought up the container again and in another terminal ran the exec command. Once in I installed some useful things that were missing from the slim ubuntu containers.
apt install vim
apt install gdbMy next test was whether I could recreate the issue under GDB and with the python faulthandler . I edited the main file (run.py) and added import faulthandler at the top and main the first line after the api had started to be faulthandler.enable().Then I initialised gdb and ran my main script and then the test harness in my testing terminal. Within the running container:
> gdb python3
(gdb) run run.py This correctly ran the application and bound it to the ports. Now for the moment of truth, would I be able to recreate the error with debugging on? Running my 10 test in parallel I waited and watched the output. GDB gave me lots of extra information and I could see the threads being created and destroyed as the model classified the images. It didn’t fail as quickly as it had without gdb, but it did fail in the same way and this time I had the trace.
Understanding the trace
Looking at the last bottom of the output, I could immediately see some clues as to what was happening:
corrupted size vs. prev_size
Fatal Python error: AbortedThen there was a very large stack trace as each of the threads were stopped. One of these threads was different to all the others and that immediately stood out to me:
Thread 0x00007f68fd5ad700 (most recent call first):
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/conv.py", line 320 in forward
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 489 in __call__
File "/code/services/wideresnet.py", line 42 in forward
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 489 in __call__
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/container.py", line 92 in forward
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 489 in __call__
File "/code/services/wideresnet.py", line 147 in forward
File "/code/services/run_CNN.py", line 149 in forward_pass
File "/code/services/classifier.py", line 41 in get_classifier_data
File "/code/api/server.py", line 68 in classify
File "/usr/lib/python3.6/http/server.py", line 418 in handle
File "/usr/lib/python3.6/socketserver.py", line 724 in __init__
File "/usr/lib/python3.6/socketserver.py", line 364 in finish_request
File "/usr/lib/python3.6/socketserver.py", line 654 in process_request_thread
File "/usr/lib/python3.6/threading.py", line 864 in run
File "/usr/lib/python3.6/threading.py", line 916 in _bootstrap_inner
File "/usr/lib/python3.6/threading.py", line 884 in _bootstrap
File "/usr/local/lib/python3.6/dist-packages/ptvsd/visualstudio_py_debugger.py", line 2012 in new_thread_wrapper
File "/usr/local/lib/python3.6/dist-packages/ptvsd/visualstudio_py_debugger.py", line 122 in thread_starter
This thread had crashed within torch. Interesting, there were only three models that we had deployed to production that use torch and the other two would be called far less frequently. All evidence pointed to torch being the cause of the corrupted size error.
This model was using an older version of torch but I didn’t want to update without verifying the error. This is the point at which the internet can help or hinder. A google search for “torch seg fault” or “pytorch corrupted size vs previous size” gives some bad answers. Some of the posts suggest that adding:
export LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc_minimal.so.4"
will solve the problem but the majority of people posting this admit that they found it else where and don’t know why it worked, with about an equal number of posts from people saying that this solution did not work from them. Never copy and paste code without knowing what it does6. Here this is a C library that implements thread-caching memory allocation, which sounds like it might help. We definitely have an issue with threading and corrupted size could be a memory. But, given that most people couldn’t explain why it worked – what precisely was this fixing? – and that there were many people who had the problem after adding this code, I wanted to search further.
My next point was to dig deeper – what within torch conv.py was not thread safe? So following the clues in the debug – line 320 of conv.py in the version of torch I was installing with the docker was a call to nn.Conv2d(). A google for that gave:
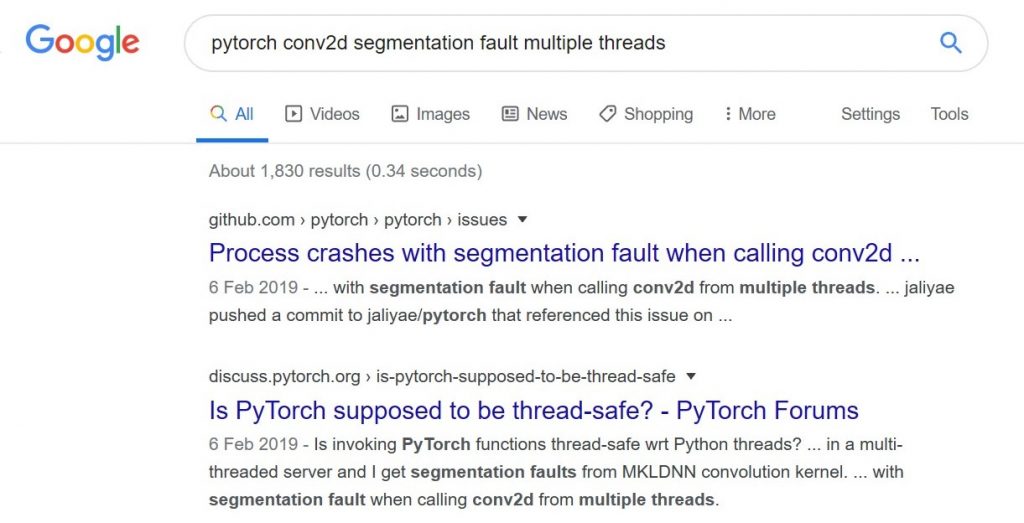
Aha, this sounds familiar, a recent (one year old) bug report with this exact issue with the version of pytorch in our container (v1.0.1) and a pull request with an explanation. Ideally here I would not want to upgrade the whole code to the latest version because a lot of other things would change and it’s always best to test fixes in isolation. However, this was a live system producing failures and there wasn’t time to build and test a version of PyTorch with the fix in, so I rebuilt the docker container with the latest versions of pytorch (1.4.0) and torchvision (0.5.0) and hoped that nothing else would break.
With an updated docker container I went through my recreation steps, firstly to check that the model worked correctly with a single test call and then ramping up. At 10 parallel calls I could not get it to error. But I wanted to be sure. I upped the tester to twenty and then thirty calls in parallel and still the docker container handled them. At 427 parallel test runs with still no error I was satisfied that this was a good fix and nothing else was broken buy the update. I asked my team to update the other two models using this older version of torch and we pushed them out to live.
Takeaway learnings
While upgrading to the latest versions of our libraries would have solved this problem, it may have introduced others and started a terrible cycle of debugging and diagnosing with a constantly changing codebase. Here are my tips for diagnostics:
- Ask what has changed
- Recreate locally
- Run in debug
- Isolate the point of the error
- If you can’t fix the error directly, then search for it
- Only implement fixes that you understand
- Verify that the change solves the error, if not back out all changes and try something else
I hope this helps. Diagnositics, just like testing, is a different skill to development and needs practise to learn. Don’t be afraid to dive in and verify the root cause with a few changes as possible.
- I’ve done a lot of hard work to get this set up, I’m currently writing a book on best practise for testing and I’ll detail it in there if I haven’t done another post about it before then. ↩
- Fun for me at least 😉 ↩
- By a lot, we’re talking about 70 thousand occurrences in 24 hours, fortunately Sentry only emails the first time these things happen 😀 ↩
- The overhead of a single extra function call can be enough to remove an intermittent timing error in complex threaded code. ↩
- I work on Ubuntu 18.04, mostly in command line. ↩
- I wish I didn’t have to say this, but I see it over and over again… ↩
- Obviously the perfect number at which to stop… ↩