
A few days ago, researchers from Facebook published a paper on a deep learning technique to create “natural images”, with the result being that human subjects were convinced 40% of the time that they were looking at a real image rather than an automatically generated one. When I saw the tweet linking this, one of the comments1 indicated that you’d “need a PhD to understand” the paper, and thus make any use of the code Facebook may release.
I’ve always been a big believer in knowledge being accessible both from being freely available (as their paper is) and also that any individual who wants to understand the concepts presented should be able to, even if they don’t have extensive training in that specialism. So, as someone who does have a PhD and who is in the deep learning space, challenge accepted and here I’ll discuss what Facebook have done in a way that doesn’t require advanced degrees, but rather just a healthy interest in the field2.
Firstly, what is the point of the research? Samples of natural images, properly categorised and tagged are an essential starting point for any deep learning project. Without this, you need to use either one of the publicly available data sets3 or create your own with the time and expense this involves. If we could find a way to generate images reliably that are of the same quality as “real” (directly photographed) images then we can shortcut some of the creation process. Also, while we are able to imagine or dream any situation, we currently rely on manual photo manipulation to turn this into something we can share – we will get to a point where you can say “ok Google4 show me riding a bicycle on mars” and a realistic representation is produced. Generating images is an area of deep learning that has not progressed as quickly as image classification tasks.
So how do you go about creating an image? There are currently 2 approaches: use training images to understand relationships within images and so recreate using building blocks blending the edges, or create textures and use these to blend an image. The deep learning approaches to image generation have focused on creating textures5.
Now to the guts of it. If you read the approach section of the paper and don’t have the maths to follow it I can image you’d be a little put off. This can be explained far more simply with the aid of a diagram.
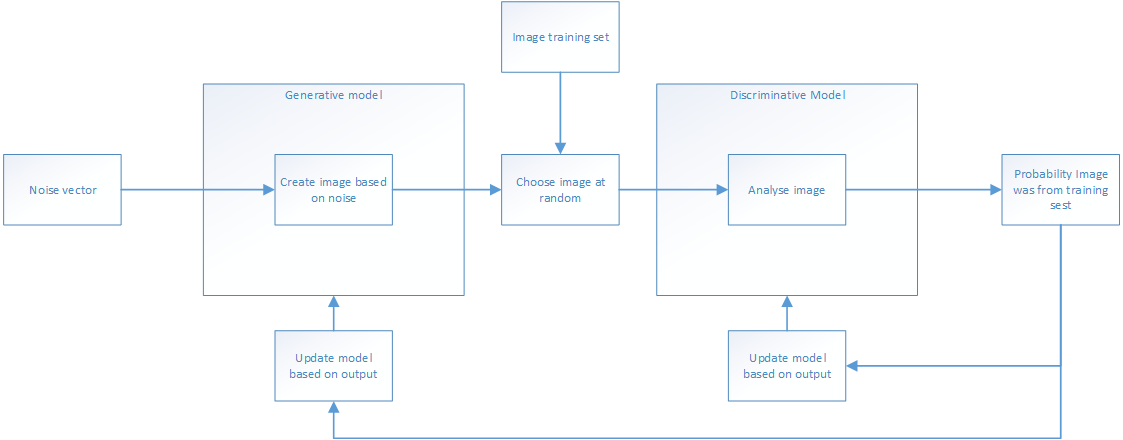 We have two networks in parallel. The first is trained to produce images from “noise”, while the second is trained to distinguish “real” images from those created by the first network. The output of the second is a probability of whether the image was real or generated. By using the accuracy of the output to adjust both networks, simultaneously we train the network producing images to get better at fooling the network deciding the source of the image, while also training the decision making network to get better as spotting fake images. So both get better.
We have two networks in parallel. The first is trained to produce images from “noise”, while the second is trained to distinguish “real” images from those created by the first network. The output of the second is a probability of whether the image was real or generated. By using the accuracy of the output to adjust both networks, simultaneously we train the network producing images to get better at fooling the network deciding the source of the image, while also training the decision making network to get better as spotting fake images. So both get better.
The detail of how the images are generated from noise is fascinating. Firstly consider creating a smaller image from a larger one: as you make the image smaller, you lose information, and this can be adjusted depending on the sampling. Going back to a larger image is much more difficult as we are creating information. This is like trying to work out how you get the number 42 with no knowledge of what numbers or even what operators you started with – or Jeopardy only where there are multiple correct answers. Since each new level depends on the previous, the decisions made can have big impacts.
To train the generating model, the team decreased the image by a factor of 2 (throwing away the lost information) and then increased it back using their generation algorithms. This output was then tested by giving the decision network the original or the regenerated image. The down- and up-scaling is repeated until the 64×64 image is 8×8, which is the random noise that the team were feeding in to the network. What is novel about their approach to the up scaling was a combination of two different methods6 which has given images that are “more object-like and with more clearly defined edges”7.
Setting aside the issue of architecture tuning, the team used three sample data sets to train and experiment on their networks, when the 64×64 images were shown to 15 human volunteers with a simple interface for “Real” or “Fake”, they discovered about 40% of the generated images could fool the humans (compared to 90% for real images).
While there is is clearly a long way to go from 40% success at 64 x 64 px to realistic images for training data this is a great step forward. The code has been released and is available on GitHub. The community will benefit from more examples of cutting edge research and the ability to apply this quickly to other areas. I’d love to see this used to reconstruct sound for example. If you’d like to know more, I’d encourage you to read the paper and look at the sample images.
- Sadly this is lost into oblivion on my twitter feed so I can’t credit the person who inspired this blog post ↩
- For references, please see links from Facebook’s paper ↩
- Which are fine if you want to build something that somebody else has already ↩
- Or whichever voice activated AI you prefer ↩
- If you want to read more, the links in the paper give a really good summary of the different approaches and their limitations ↩
- Generative Adversarial Networks and Laplacian Pyramids ↩
- Directly quoted from http://arxiv.org/pdf/1506.05751v1.pdf ↩