This post is a very high level summary of Day 2 at the Boston ReWork Deep Learning Summit 2015. Day 1 can be found here.
The first session kicked off with Kevin O’Brian from GreatHorn. There are 3 major problems facing the infosec community at the moment:
- Modern infrastructure is far more complex than it used to be – we are using AWS, Azure as extensions of our physical networks and spaces such as GitHub as code repositories and Docker for automation. It is very difficult for any IT professional to keep up with all of the potential vulnerabilities and ensure that everything is secure.
- (Security) Technical debt – there is too much to monitor/fix even if business released the time and funds to address it.
- Shortfall in skilled people – there is a 1.5 million shortage in infosec people – this isn’t going to be resolved quickly.
So there needs to be another solution. Combine these problems with the increasing efficiency and organisation of attacks on businesses. Groups try out new attacks on one business and, if successful, quickly apply the same techniques to similar businesses, can humans keep up with this? There are multiple techniques to identify threats for fast response, but also need to ensure that basic security is covered too: minimum permissions given to users for what they need to achieve and basic password protocols. Then linear regression can identify unusual behaviour in e.g. login times, with deep learning to recognise and predict attack patterns. Data can be flagged as sensitive without the need to look at the contents. This should be part of any IT manager’s tool kit alongside business continuity.
Paul Murphy from Clarify gave the morning’s second talk – another speech and machine learning combination but from a different angle. He had some wonderfully drawn slides to accompany his history of machine learning and there was a great point here that some of the biggest advances came when teams used processes from areas outside of their specialisation. A great example of this is the crossover of noise processing between image and speech recognition.
At Clarify they have an API for speech recognition that has been trained to understand even heavily accented English and local adapations. One of their key problems was how to deal with changes in attenuation, especially during conference calls. They are slowly bringing in machine learning but are still far from the 95% goal. One to watch maybe.
The third talk was from Meng Wang who co-founded Orbeus, which does a combination of face recognition, OCR, concept tagging to allow users to organise and post images to and from multiple sources. he made a fantastic point that real world problems need real world data and cannot be solved with a lab data set, so he paused his PhD to found Orbeus and train a system with real images. Their system was able to find similar images by looking at genuine similarity rather than tags. He showed how a search on a picture of a daisy gave very close matches, while Google image search returned tagged daisy images in its own order.
He also spoke about their architecture and that the jump from a single GPU to a 16 GPU system decreased the training time from 3 months to 6 days, making their training more efficient, and that they had a “golden” test set they kept for evaluation only and didn’t use for training.
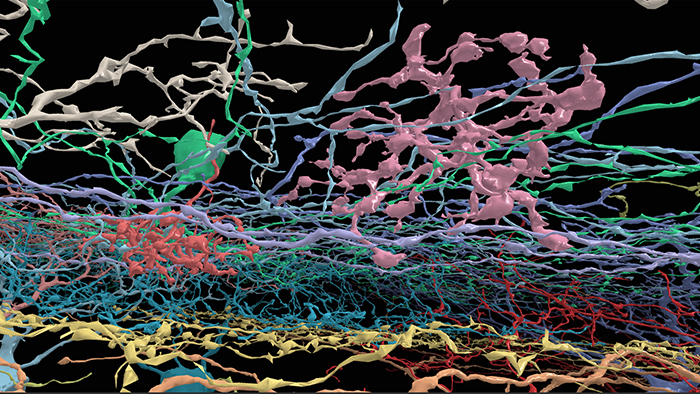
The final talk of this session was from EyeWire who have used deep learning as part of a project to map neuron boundaries in the retina. In contrast to many of the other companies presenting, they have a system set up to run on CPUs rather than GPUs that is computationally efficient, looking at a 3D problem. They’ve created a game, which is essentially a 3D colouring book and is one of the most addictive games I’ve played (I got “the Insane” achievement on World of Warcraft pre-nerf so I know a thing or two about addiction in gaming!). One of the best things about the game is that by helping to map the neurons, you’re directly contributing to understanding the science of biological image processing. If you’re one of the lucky ones who have a pre-release Oculus Rift then they have a great demo of 17 of the mapped neurons – Neuron Safari – I’ve played this and it’s a really good showcase of the complexity of neurons generally.
The second half of the morning started with Aude Oliva from MIT discussing scene recognition. Much research has been done on object recognition and classification but biochemical research shows that humans perceive places first and then the objects within them in context, with our attention focusing on anything out of the ordinary. This is why we can find something funny without always knowing why, or a subconcious adrenaline rush before we know what the danger is. MIT have creates a 1M image set of categorised scenes called “places”, which they have used for training. Scenes can look very different with multiple view points, different lighting levels, different objects etc. They discovered that by training the neural network on places, they got object detection for free as an emergent property, with parts of the network optimised for wheels, crowds or even legs. Without trying, they had created properties that were very interesting in the network and this makes me wonder if other neural networks could have similarly useful emergent properties if we trained on more abstract problems… I’ll definitely be reading the papers for this research carefully.
I was not prepared for the next talk :). Ryan Adams from Harvard was discussing how his team had created a black box tool to take the dark arts of turning machine learning into a more scientific process. I’d been waiting for this talk because, as Ryan himself noted in his opening statements, “not everyone can get a Hinton grad student”. I wrote down notes as fast as I could, but Ryan is a very commanding speaker and was conveying a lot of fantastic information very quickly – I was reminded of being back at Oxford as an undergrad with some of the better lecturers there just absorbing as much information as I could. If you get a chance to go to one of his talks make sure you are awake and fully attentive – you won’t regret it. Generally, Machine Learning is becoming less and less accessible to non-experts – the details of how to set up and tune the networks are not covered in the published papers, which is why you need to find people very experienced. For start-ups like mine, this is a huge problem – we’re not well known enough to attract talent when the big players (Twitter, Google and even smaller players with cool applications like EyeWire and MetaMind) are hiring. So what can we do? They’ve created a spin out company called WhetLab that enables non-experts to optimise their networks. The WhetLab code uses Bayesian Optimisation to find the optimum values for the parameters. These cycles can be done on proxy models much more quickly than the full training set and their API allows anyone to use this technique to help with their networks. If you want to dive into the tech then have a look at their website as I can’t do it justice in summary.
Next up was Aaron Steele from the World Resources Institute – a not for profit looking at global deforestation. In an industry that can be so focused on killer apps and return on investment, it warms the soul to see people using technology (albeit resulting from the corporate race) to better the lives of all. Although global CO2 has always fluctuated, it has always had a maximum peak of 300 ppmv before dropping… until recently. Last month, global CO2 hit 400 ppmv for the first time in history (and that’s going back a long way with ice core data). We are depositing carbon into the atmosphere and this will have an effect (something that is far better documented elsewhere if you want to look at the arguments). However, the WRI are looking at deforestation with two projects – UMD that has high resolution but only updates annually, and Forma that has lower resolution (250m squared) but can be updated fortnightly. The latter project has the ability to inform governments (and businesses in some cases) to allow fast action. Using 12 years worth of data, and current imagery from their partners, Orbital Insight, they are building a machine learning system to make predictions for deforestation and faster alerts. Aaron ended with a showcase of the number of projects that could benefit from deep learning on their data – amazing stuff and a worthwhile cause.
The fourth talk of this session was from Olexandr Isayev from the University of North Carolina. The number of new drugs created per billion dollars of investment has been falling dramatically, with it now taken over a billion to create a single treatment. I can’t recall if anyone asked if the values had been normalised for inflation, but regardless, the y-axis on the graph was logarithmic, so even if inflation hadn’t been taken into account then it would still have showed a strong fall. There are many reasons for this and chemists are having to deal with extraordinarily large data sets of potential chemicals, with new ones being logged to the database regularly. How can this be reduced intelligently? By representing the complex 3D structure of the chemical and its properties as parameters, these data sets can be fed into the deep learning algorithm to filter out 99% of the irrelevant chemicals and leave a much more manageable data set to work on. The results looked fascinating and the biochemist in me wanted to find out more about the chemical analysis and matching, but this was the wrong conference for that ;).

After lunch we were into the home straight, starting with Dhruv Batra from Virginia Tech. One of the reasons that AI is bad is that it cannot comprehend a scene. He showed this picture of Obama. To a human it’s amusing, but to a computer? It’s a difficult image to process: there are significant reflections and patterns and lots of similarly dressed individuals. A good engine might give you “business men”, a better one might spot “locker room”, “weighing” and even facial recognition for the emotion “laughing” and that it is Obama. But still, with all those tags, the essence of the picture is lost. The humour requires knowledge of physics (stepping on the scale will make it weigh more), culture (middle aged men may be sensitive about their weight), elements of surprise (Nicholson is unaware what Obama is doing) and protocol (this is an unusual act for a President).
This theory can also be applied to natural language. Take the phrase “I saw her duck” and most people would think that duck was the noun. A second slightly less common meaning would be that duck is a verb. A far less common interpretation would be that “saw” is a present tense of “sawing” rather than a past tense of “seeing”. The aim of Dhruv’s research was to show a computer a picture and ask a natural question about it to see if there could be an answer. Their system had to recognise the image and also process the question correctly to give the (impressive) answers. This was great to see as it was one of the things Andrew Ng spoke about vaguely in his talk on day 1 while this talk contained some substance. I suggest you find the paper and read up.
Jianxiong Xiao from Princeton was next to speak with a very entertaining talk on moving beyond 2D object recognition. With a flat image, data can be lost and we have to make assumptions. The human brain is very good at this, if we see an object from an unusual angle, we generally are able to identify it correctly but this is something that machines find difficult. Jianxiong and his team created a set of 3D shapes of lots of different objects and used this to train a deep learning engine. With this, they were able to take a 2D image and extract the appropriate 3D object shape. They could also “hallucinate” the missing parts of the object before trying to match it – very powerful stuff.
What makes an image memorable is something that marketeers have been trying to grasp for a long time as 90% of the internet’s traffic is visual. Aditya Khosla from MIT is doing his PhD on this and asked the question “Is it possible to predict what images people will remember?” This has a lot of potential applications: from the banal “perfect” selfie-selection to advertising to education. He had run an experiment using 100 images and asked people to see whether they had seen it before. He tried a much shorter version of the experiment with us, asking us to clap if we’d seen an image before. While there were a few mis-claps in the audience (you know who you are!) as a group, we got it right. It did require concentration so I can image it does get more difficult with more images and longer time periods.
Was memorability a property of the image or the individual? The tests showed that it is the image and is instrinsic and measurable, with a high correlation of which images were best remembered between randomised groups. The best images were focused and close, with the more forgettable images being landscapes. Memorability was distinct from aesthetic quality. Unusual images had high memorability, as did those that provoke disgust. With this data, they trained a deep learning network, which managed to predict the memorability of images very close the human values. When given images, humans are very bad at predicting memorability, but their trained system they are starting to predict this. Well worth looking at the statistics behind this for anyone interesting in image choice.
Next up was Devavrat Shah, also of MIT talking about Bayesian regression as applied to decision making. There is a large problem for chain stores in determining what stock, and how much, to send to which stores. This is a complex computational prediction and there are many factors outside of consumer buying habits that may affect this (economic changes, unexpected weather etc). It’s a big problem, but not enough structured data to create a machine learning solution, so the team looked at something that did have structured data: Bitcoin trading values in different locations over 5 months. this gave over 200M data points for training. The system had a position of trading +1, 0, -1 Bitcoins for simplicity, rather than having a stronger position, with a simple prediction of price increase or decrease. The results were promising with the system making an 89% profit over a 50 day term. While there have been problems with AI in trading situations e.g. contributing factors to the 2010 Flash Crash) these are here to stay, so finding a good model of prediction would be very valuable.
The last talk of the day, and indeed the summit was given by Alexander Schwing from the University of Toronto on structured prediction. Given and image set, we want to understand the scene, the contents (tags) of the image and segmentations, all of which have very large output spaces. At this point, the standard models start to fall down and a different approach is needed. Alexander outlined a blended training approach to a structured model to decrease the potential output space. This was interesting although I think it’s too early for using these techniques on general machine learning problems.
And that was how it ended. Two days of great intellectual presentations and discussion. A fantastic meeting of minds and collaboration of ideas. I was impressed with the quality of the whole event and would encourage you to go to any of the ReWork events that match your interests. The next Deep Learning summit is in London in September and who knows, I may even be speaking myself at one of these soon…