Today, after a lot of pondering I finally signed up for MST210 to start in October. This is the second 60 point module and, just like M208, is mandatory on the BSc Maths pathway. I’d been holding back for a number of reasons and reviewing my post from last year, I realised that nothing had changed. If anything my job is now more mathematically demanding as I dig deeper into the bleeding edge internals of machine learning. My 3D printer is nearly finished and my daily commute is now 3 hours a day, giving me 2 hours a day sitting on trains. That time is currently occupied with getting through a ridiculous amount of books1. What I really want to avoid with MST210 is some of the rushing that I did for M208 – I want to enjoy this module. Continue reading MST210 – mathematical modelling – registered
Example from the MNIST data set used in this experiment
After my introductory post on Literate Programming, it occurred to me that while the concept of being able to create documentation that includes variables from the code being run is amazing, this will obviously have some impact on performance. At best, this would be the resource required to compile the document as if it was static, while the “at worst” scenario is conceptually unbounded. Somewhere along the way, pweave is adding extra code to pass the variables back and forth between the python and the , how and when it does this could have implications that you wouldn’t see in a simple example but could be catastrophic when running the kind of neural nets that my department are putting together. So, being a scientist, I decided to run a few experiments….1Continue reading Literate programming – effect on performance
Over my career in IT there have been a lot of changes in documentation practises, from the heavy detailed design up front to lean1 and now the adoption of literate programming, particularly in research (and somewhat contained to it because of the reliance on as a markup language2). While there are plenty of getting started guides out there, this post is primarily about why I’m adopting it for my new Science and Innovations department and the benefits that literate programming can give. Continue reading Using Literate Programming in Research
It’s true. Image from Andy Glover http://cartoontester.blogspot.com/
As part of a few hours catching up on machine learning conference videos, I found this great talk on what can go wrong with machine recommendations and how testing can be improved. Evan gives some great examples of where the algorithms can give unintended outputs. In some cases this is an emergent property of correlations in the data, and in others, it’s down to missing examples in the test set. While the talk is entertaining and shows some very important examples, it made me realise something that has been missing. The machine learning community, having grown out of academia, does not have the same rigour of developmental processes as standard software development.
Regardless of the type of machine learning employed, testing and quantification of results is all down to the test set that is used. Accuracy against the test set, simpler architectures, fewer training examples are the focal points. If the test set is lacking, this is not uncovered as part of the process. Models that show high precision and recall can often fail when “real” data is passed through them. Sometimes in spectacular ways as outlined in Evan’s talk: adjusting pricing for Mac users, Amazon recommending inappropriate products or Facebook’s misclassification of people. These problems are either solved with manual hacks after the algorithms have run or by adding specific issues to the test set. While there are businesses that take the same approach with their software, they are thankfully few and far between and most companies now use some form of continuous integration, automated testing and then rigorous manual testing.
The only part of this process that will truly solve the problem is the addition of rigorous manual testing by professional testers. Good testers are very hard to find, in some respect harder than it is to find good developers. Testing is often seen as a second class profession to development and I feel this is really unfair. Good testers can understand the application they are testing on multiple levels, create the automated functional tests and make sure that everything you expect to work, works. But they also know how to stress an application – push it well beyond what it was designed to do, just to see whether these cases will be handled. What assumptions were made that can be challenged. A really good tester will see deficiencies in test sets and think “what happens if…”, they’ll sneak the bizarre examples in for the challenge.
One of the most difficult things about being a tester in the machine learning space is that in order to understand all the ways in which things can go wrong, you do need some appreciation of how the underlying system works, rather than a complete black box. Knowing that most vision networks look for edges would prompt a good tester to throw in random patterns, from animal prints to static noise. A good tester would look of examples not covered by the test set and make sure the negatives far outweigh the samples the developers used to create the model.
So where are all the specialist testers for machine learning? I think the industry really needs them before we have (any more) decision engines in our lives that have hidden issues waiting to emerge…
Following my post on AI for understanding ambiguity, I got into a discussion with a friend covering the limitations of AI if we only try to emulate ourselves. His premise was that we know so little about how our brains actually enable us to have our rich independent thoughts that if we constrain AI to what we observe, an ability to converse in our native language and perform tasks that we can do with higher precision, then we will completely limit their potential. I had a similar conversation in the summer of 2015 while at the start-up company I joined1– we spent a whole day2 discussing whether in 100 years’ time the only jobs that humans would do would be to code the robots. While the technological revolution is changing how we live and work, and yes it will remove some jobs and create others just like the industrial revolution did and ongoing machine automation has been doing, there will always be a rich variety of new roles that require our unique skills and imagination, our ability to adapt and look beyond what we know. Continue reading Evolving Machines
Sometimes being part of a minority gender in IT is really beneficial. There’s always plenty of people wanting to talk to you at conferences (and never a queue for the toilets!) and it can be quite nice being a novelty. Also, on just about every business trip I go on, I’m reminded of the fact that when people see me, they don’t expect me to be in IT, let alone have a senior position. Today, I had to laugh as a couple of businessmen on the table next to me gave me a lot of detail about their company confidential research that is directly useful to what I’m doing.
Fistly, I didn’t need over 5 years as CTO/CIO to learn the basics of business security. Anyone in the industry knows that you don’t go blabbing confidential information in public, or do they? It’s one of the easiest ways of social engineering – hang around in bars, coffee shops etc near an office that interests you and overhear what you can. Some of it may be useful.
Chief Science Officers have a lot to live up to… (image credit Wikipedia)
I’ve been with my current company for 9 months as Chief Information Officer and had responsibility for everything technical from production systems down to ensuring the phone systems worked and everything in between. The only technical responsibilities not under me was the actual development and QA of our products. CIO is a thankless role – when everything is going right, questions are raised over the size of the team and the need to replace servers and budget for new projects. When something breaks, for whatever reason, you are the focus of the negativity until it is resolved. The past 9 months have been a rollercoaster of business needs, including many sleepless nights. However, I can look back on this knowing that when I do finally get around to writing about my experiences as a woman in IT I will have a lot of fun stories for the CIO chapter1. While I didn’t have the opportunity to finish off as many of the improvement projects as I would have liked, I’ve built up a fantastic team and know that they’ll continue to do a fantastic job going forward.
This week, I finished the handover of all my old responsibilities and started the role I was actually hired for back in 2015, but didn’t start with because the business needed a strong pair of hands elsewhere. I am now Chief Science Officer and have a new team of Computer Vision researchers and am taking over all of the data science and machine learning activities worldwide. I’ve been given a remit of thought leadership with the team, so I’ll be attending (and speaking at) conferences, writing blog posts, publishing papers and let’s not forget that I’ll be neck deep in the research myself, leading a team of academics within a corporate environment on computer science research.
While I won’t be able to talk about what we’re doing until we’re ready to make it public, I will be blogging about the kit we’re using and some generic machine learning issues, as well as interesting papers as and when I find them.
It’s going to be a pretty exciting time – there are several cool projects that we’ve started and I’ve given myself some harsh deadlines so that we can have some results ready for a conference…
At the end of my last post in this series, we had added the print head to the main frame and created the filament spool. This post focuses on the top cover, filament guide and hood, covering issues 77-81 of 3D Create and Print by Eaglemoss Technology. If you’ve skipped a part of this series you can start from the beginning, including details of the Vector 3 printer I’m building on my 3D printer page. Some of these issues do not have build instructions but instead provide instructions on calibrating the printer and preparing for the first print, which I’ll cover in part 21. You will need all the parts from these 5 issues, but the instructions are in issues 77, 78 and 81. Continue reading 3D Printer Part 20: Top cover and hood
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.

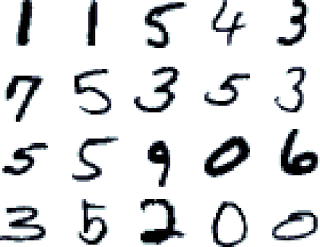
 document as if it was static, while the “at worst” scenario is conceptually unbounded. Somewhere along the way, pweave is adding extra code to pass the variables back and forth between the python and the
document as if it was static, while the “at worst” scenario is conceptually unbounded. Somewhere along the way, pweave is adding extra code to pass the variables back and forth between the python and the