Is there the perfect mum? Dove’s Aimee is AI’s created image based on what the media think she should be (c) Dove
Earlier this month, Dove launched their new baby range with another of their fantastic adverts challenging stereotypes and questioning is there a “perfect mum”. As a mum myself I can relate to the many hilarious bloggers1 who are refreshingly honest about the unbrushed hair, lack of make-up, generally being covered in whatever substances your new tiny human decides to produce, and all other parenting frustrations. I’m really pleased that there are lots of women2 out there challenging the myths presented in the media – we don’t all have a team to make us beautiful, nor someone photo-shopping the results to perfection, and the pressure can be immense. This is where Dove’s campaign is fantastic. Rather than just creating a photoshoot with a model and doctoring the results, the image is actually completely artificial, having been generated by AI. Continue reading Artifical image creation takes another step forward in advertising
(c) Parliament committee on Science and Technology
I love the fact that here in the UK everyone can be involved in shaping the future of our country, even if a large number of individuals choose not to and, in my eyes, if you don’t get involved then you don’t have the right to complain. While this is most generally applied to the election of our representatives from local parish councils to our regional MPs (or actually standing yourself)1 there are also a lot of other ways to be involved. In addition to raising issues with your local representative, parliament has cross bench committees that seek input from the public and to help create policy or consider draft legislation.
Our elected parliament is not made up of individuals who are experts in all fields. Even government departments are not necessarily headed by individuals with large amounts of relevant experience. It is critical that these individuals are informed by those with the experience and expertise in the issues that are being considered. Without this critical input, our democracy is weakened. Continue reading Submitting evidence to parliament committees
The matrix, well a matrix… A confusion matrix for a 60 class network running on the Dell XPS laptop
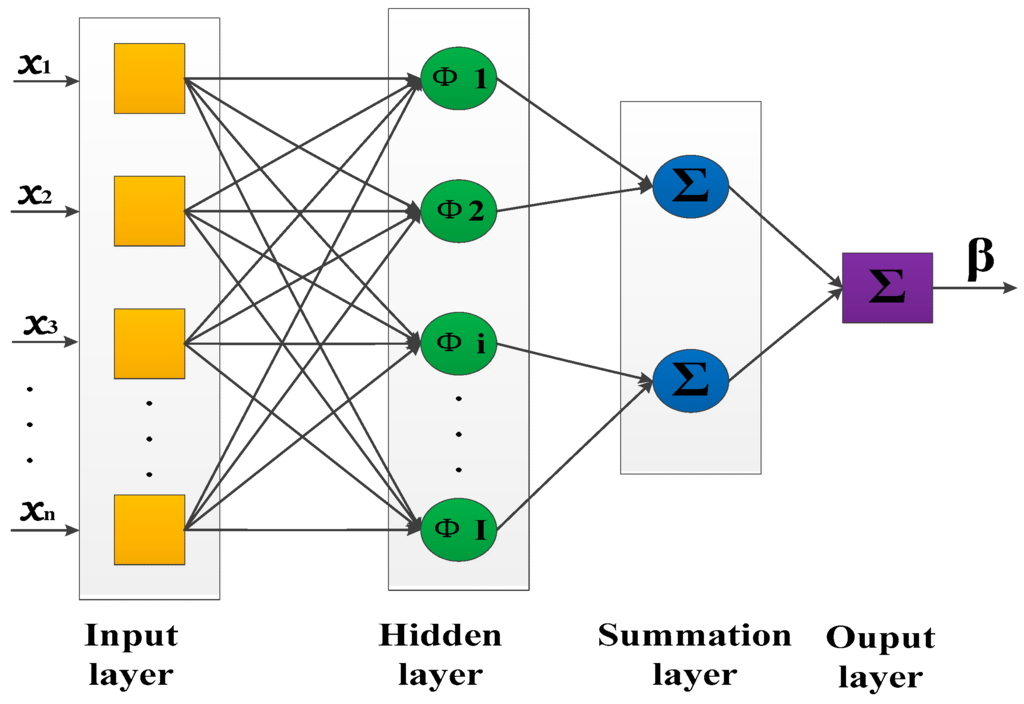
If you’re starting out in deep learning and would prefer a laptop over a desktop, basic research will lead you to a whole host of blogs, Q&A sites and opinions that basically amount to “don’t do it” and to get a desktop or remote into a server instead. However, if you want a laptop, whether this is for college, conferences or even because you have a job where you can work from anywhere, then there are plenty of options available to you. Here I’ll lay out what I chose and why, along with how it’s performing. Continue reading Choosing a Laptop for Deep Learning Development
Could you explain to a lay person how this network makes decisions?
The Science and Technology Select Committee here in the UK have launched an inquiry into the use of algorithms in public and business decision making and are asking for written evidence on a number of topics. One of these topics is best-practise in algorithmic decision making and one of the specific points they highlight is whether this can be done in a ‘transparent’ or ‘accountable’ way1. If there was such transparency then the decisions made could be understood and challenged.
It’s an interesting idea. On the surface, it seems reasonable that we should understand the decisions to verify and trust the algorithms, but the practicality of this is where the problem lies. Continue reading Algorithmic transparency – is it even possible?
Loom.ai can generate a 3D avatar from a single image
“Pics or it didn’t happen” – it’s a common request when telling a tale that might be considered exaggerated. Usually, supplying a picture or video of the event is enough to convince your audience that you’re telling the truth. However, we’ve been living in an age of Photoshop for a while and it has (or really should!!!) become habit to check Snopes and other sites before believing even simple images1 – they even have a tag for debunked images due to photoshopping. Continue reading Artificial images: seeing is no longer believing
In September 2016, the ReWork team organised another deep learning conference in London. This is the third of their conferences I have attended and each time they continue to be a fantastic cross section of academia, enterprise research and start-ups. As usual, I took a large amount of notes on both days and I’ll be putting these up as separate posts, this one covers the morning of day 1. For reference, the notes from previous events can be found here: Boston 2015, Boston 2016.
Day one began with a brief introduction from Neil Lawrence, who has just moved from the University of Sheffield to Amazon research in Cambridge. Rather strangely, his introduction finished with him introducing himself, which we all found funny. His talk was titled the “Data Delusion” and started with a brief history of how digital data has exploded. By 2002, SVM papers dominated NIPs, but there wasn’t the level of data to make these systems work. There was a great analogy with the steam engine, originally invented by Thomas Newcomen in 1712 for pumping out tin mines, but it was hugely inefficient due to the amount of coal required. James Watt took the design and improved on it by adding the condenser, which (in combination with efficient coal distribution) led to the industrial revolution1. Machine learning now needs its “condenser” moment.
When I attended the ReWork Deep Learning conference in Boston in May 2016, one of the most interesting talks was about the Echo and the Alexa personal assistant from Amazon. As someone whose day job is AI, it seemed only right that I surround myself by as much as possible from other companies. This week, after it being on back order for a while, it finally arrived. At £50, the Echo Dot is a reasonable price, with the only negative I was aware of before ordering being that the sound quality “wasn’t great” from a reviewer. Continue reading Amazon Echo Dot (second generation): Review
It’s true. Image from Andy Glover http://cartoontester.blogspot.com/
As part of a few hours catching up on machine learning conference videos, I found this great talk on what can go wrong with machine recommendations and how testing can be improved. Evan gives some great examples of where the algorithms can give unintended outputs. In some cases this is an emergent property of correlations in the data, and in others, it’s down to missing examples in the test set. While the talk is entertaining and shows some very important examples, it made me realise something that has been missing. The machine learning community, having grown out of academia, does not have the same rigour of developmental processes as standard software development.
Regardless of the type of machine learning employed, testing and quantification of results is all down to the test set that is used. Accuracy against the test set, simpler architectures, fewer training examples are the focal points. If the test set is lacking, this is not uncovered as part of the process. Models that show high precision and recall can often fail when “real” data is passed through them. Sometimes in spectacular ways as outlined in Evan’s talk: adjusting pricing for Mac users, Amazon recommending inappropriate products or Facebook’s misclassification of people. These problems are either solved with manual hacks after the algorithms have run or by adding specific issues to the test set. While there are businesses that take the same approach with their software, they are thankfully few and far between and most companies now use some form of continuous integration, automated testing and then rigorous manual testing.
The only part of this process that will truly solve the problem is the addition of rigorous manual testing by professional testers. Good testers are very hard to find, in some respect harder than it is to find good developers. Testing is often seen as a second class profession to development and I feel this is really unfair. Good testers can understand the application they are testing on multiple levels, create the automated functional tests and make sure that everything you expect to work, works. But they also know how to stress an application – push it well beyond what it was designed to do, just to see whether these cases will be handled. What assumptions were made that can be challenged. A really good tester will see deficiencies in test sets and think “what happens if…”, they’ll sneak the bizarre examples in for the challenge.
One of the most difficult things about being a tester in the machine learning space is that in order to understand all the ways in which things can go wrong, you do need some appreciation of how the underlying system works, rather than a complete black box. Knowing that most vision networks look for edges would prompt a good tester to throw in random patterns, from animal prints to static noise. A good tester would look of examples not covered by the test set and make sure the negatives far outweigh the samples the developers used to create the model.
So where are all the specialist testers for machine learning? I think the industry really needs them before we have (any more) decision engines in our lives that have hidden issues waiting to emerge…
Following my post on AI for understanding ambiguity, I got into a discussion with a friend covering the limitations of AI if we only try to emulate ourselves. His premise was that we know so little about how our brains actually enable us to have our rich independent thoughts that if we constrain AI to what we observe, an ability to converse in our native language and perform tasks that we can do with higher precision, then we will completely limit their potential. I had a similar conversation in the summer of 2015 while at the start-up company I joined1– we spent a whole day2 discussing whether in 100 years’ time the only jobs that humans would do would be to code the robots. While the technological revolution is changing how we live and work, and yes it will remove some jobs and create others just like the industrial revolution did and ongoing machine automation has been doing, there will always be a rich variety of new roles that require our unique skills and imagination, our ability to adapt and look beyond what we know. Continue reading Evolving Machines
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.