My husband is a game developer and my contributions are usually of the sort where I look at what he’s done and say “hey wouldn’t it be great if it did this”. While these are usually positive ideas, they’re mostly a pain to code in. Today however, I was able to contribute some of my maths knowledge to help balance out one of his games.
Using an open api, he’d written a simple pokemon battle game to be used on twitch by one of our favourite streamers, FederalGhosts, and needed a way of determining player level based on the number of wins, and the number of wins required to reach the next level without recursion. While this post is specifically about the win to level relationship, you could use any progression statistic by applying scaling. Here we want to determine:
- Number of wins (w) required for a given level (l)
- The current player level (pl) given a number of wins (pw)
- Wins remaining to the next level (wr) for a player based on current wins (pw)
Let’s take a look at a few ways of doing this. Each section below has the equations and code examples in python1. Assume all code samples have the following at the top:
import math
database = [
{"name": "player1", "wins": 5},
{"name": "player2", "wins": 15},
{"name": "player3", "wins": 25}
]Static steps
The most obvious way is linear. Each level requires the same amount of wins The reason that games don’t generally do this is that in order to make the player feel like they are progressing, you want to have shorter jumps between the early levels and longer gaps as the levels go up. However, the maths (and code) is pretty simple.
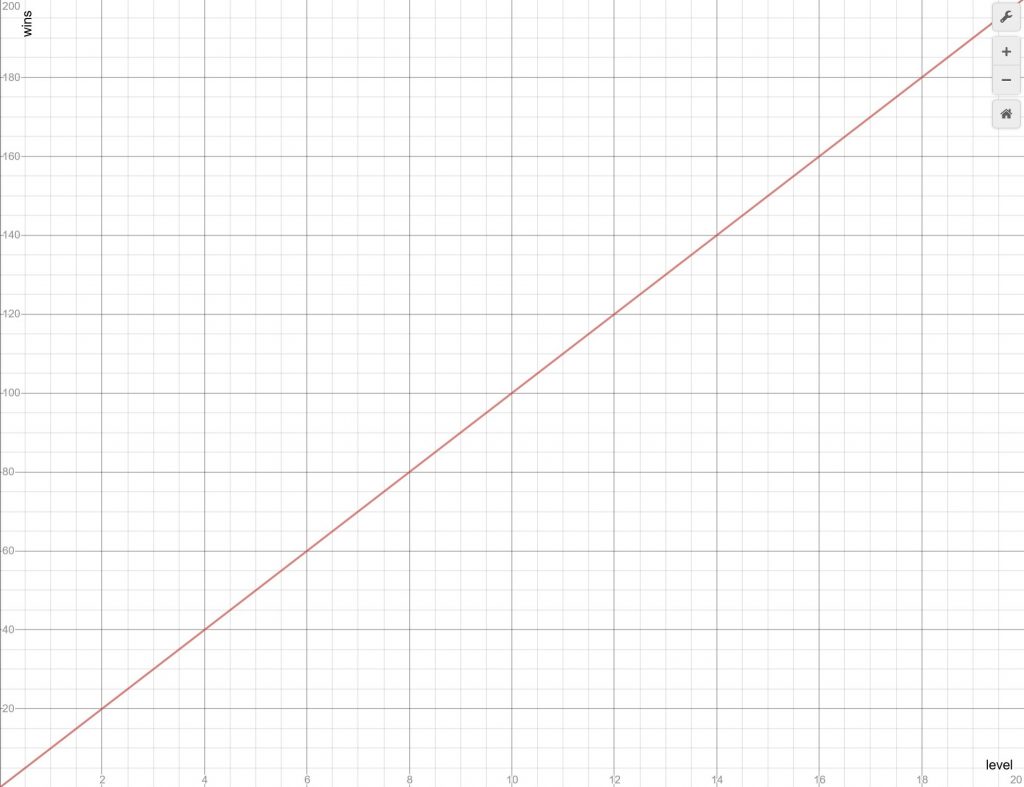
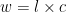
Our equations are:
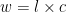
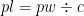

Turning that into code we get:
c = 10
for l in range(20):
w = l * c
print("level {} needs {} wins".format(l,w))
# get wins for a user and calculate level
for player in database:
pl = math.floor(player['wins'] / c) #round the level down to the nearest int
wr = ((pl + 1) * c) - player['wins']
print("{}, you are level {} and need {} wins to get to the next level".format(player['name'], pl, wr))So all pretty straight forward, if a little dull from a player point of view.
Hard coded
So, you want something non linear? It might occur to you to define the levels manually up to a cap in a list and then search through it to find the player level based on the number of wins, and anything above is maxed out. While this is conceptually an easy way of doing things, hard coding numbers in your code isn’t a good thing and could be a mighty pain if you decided to change things (e.g. change wins for health left after winning for example 2).
Here we don’t have clean formulae, you’d define your levels arbitrarily. For example:
levels = [ 0, 3, 6, 9, 12, 17, 23, 28, 32, 40, 48]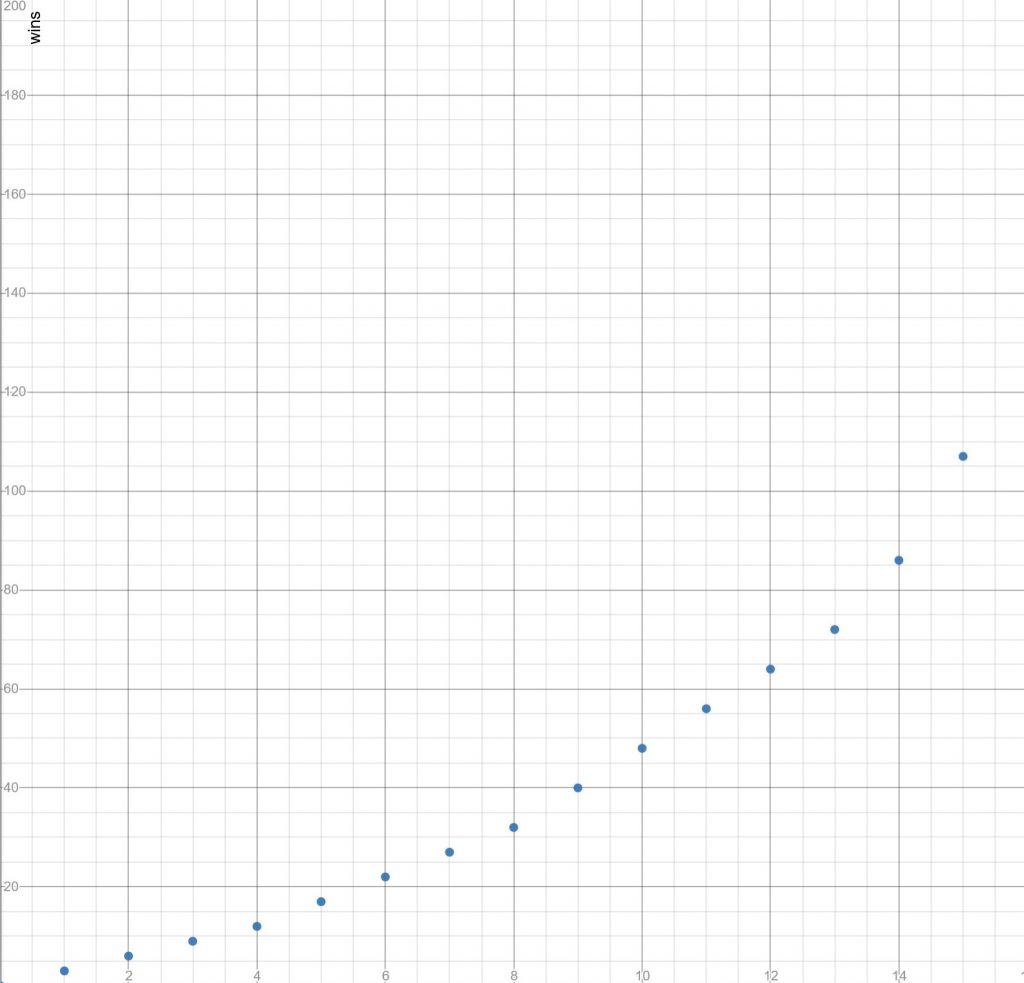
Which gives the following code to get our three answers:
for l,w in enumerate(levels):
print("level {} needs {} wins".format((l+1),w))
# get wins for a user and calculate level
#because our array starts from 0, pl is actually the index of the nth +1 element
for player in database:
pl = levels.index(min(i for i in levels if i > player['wins']))
wr = levels[pl] - player['wins']
print("{}, you are level {} and need {} wins to get to the next level".format(player['name'], pl, wr))While this is pretty straight forward you can see that getting the player level could be slow as rather than a single calculation, you’re having to do a search through an array every time. You could optimise this by starting the search at the player’s last checked level but this all feels unnecessarily clunky.
So, what solutions are more elegant?
Doubling
Setting each level to be twice as large as the previous might sound good. However, recall the Indian legend of Paal Paysam and the chess board. Starting with a single grain of rice on the first square, if you double every time you move to the next square, you will be over 1 million by the 21st square. Humans are really bad at estimating doubles. In our case, we’re only giving one point for a win, so players would quickly get to level six or seven and then get “stuck” as significantly more wins would be needed to move to the next level. That doesn’t mean that this is an invalid system. You’ll need to take into account the exceptionally large numbers as your levels (you’ll be wanting to define some unsigned long longs 😉 ) but if you are also increasing the rewards at each level at a slightly lower rate (maybe 1.5) then the game would retain difficulty as the level increases.
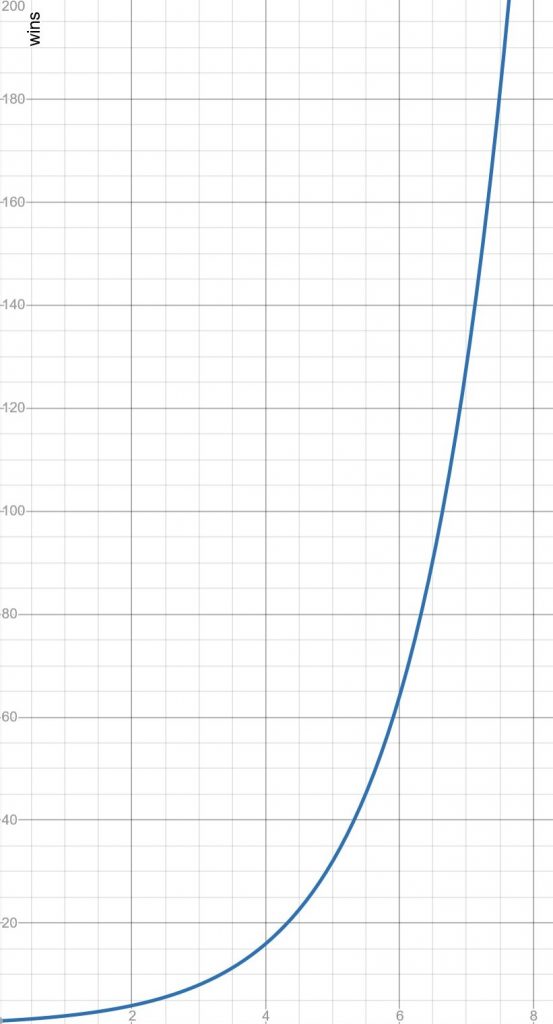
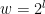

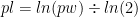
Then to get our difference to the next level we can use:
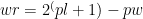
Putting into our code block this gives:
for l in range(20):
w = pow(2,l)
print("level {} needs {} wins".format(l,w))
# get wins for a user and calculate level
for player in database:
pl = math.floor(math.log(player['wins']) / math.log(2)) #round the level down to the nearest int
wr = math.pow(2,(pl + 1)) - player['wins']
print("{}, you are level {} and need {} wins to get to the next level".format(player['name'], pl, wr))
Squaring
If you’ve never studied maths then you might thing that squaring a number would grow faster than doubling. While this is true for the first few terms as soon as n = 7 you’re behind our doubling route, so this gives a gentler increase before getting wildly out of hand (level 21 is now only 441 rather than over a million). Depending on the game, you may find that this simple method works for you. If you are adding more than a single point with each event then you might want to add a scaling factor. But here the maths is simpler:
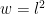
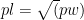
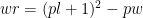
In code:
for l in range(20):
w = pow(l,2)
print("level {} needs {} wins".format(l,w))
# get wins for a user and calculate level
for player in database:
pl = math.floor(math.sqrt(player['wins'])) #round the level down to the nearest int
wr = pow((pl + 1),2) - player['wins']
print("{}, you are level {} and need {} wins to get to the next level".format(player['name'], pl, wr))Natural logarithm
If you want something a little more tricky for your players to discern3 then you can use the logarithmic functions. However as e is greater than 2, these go up faster than the doubling method, so you really need to have a system where the points awarded also scale similarly. For our purposes though:
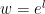
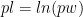

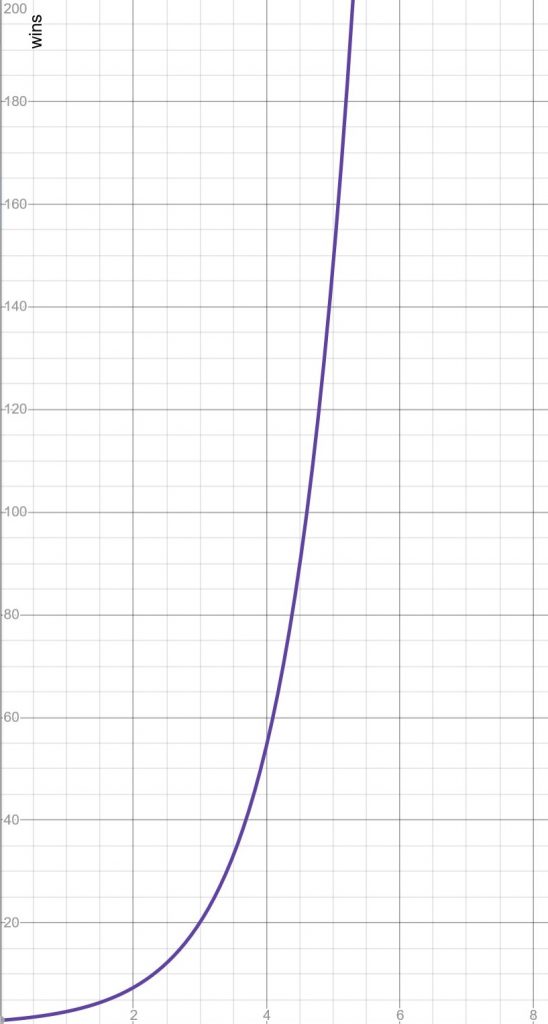
With code:
for l in range(20):
w = math.floor(math.exp(l))
print("level {} needs {} wins".format(l,w))
# get wins for a user and calculate level
for player in database:
pl = math.floor(math.log(player['wins'])) #round the level down to the nearest int
wr = math.floor(math.exp(pl + 1) - player['wins'])
print("{}, you are level {} and need {} wins to get to the next level".format(player['name'], pl, wr))What we used
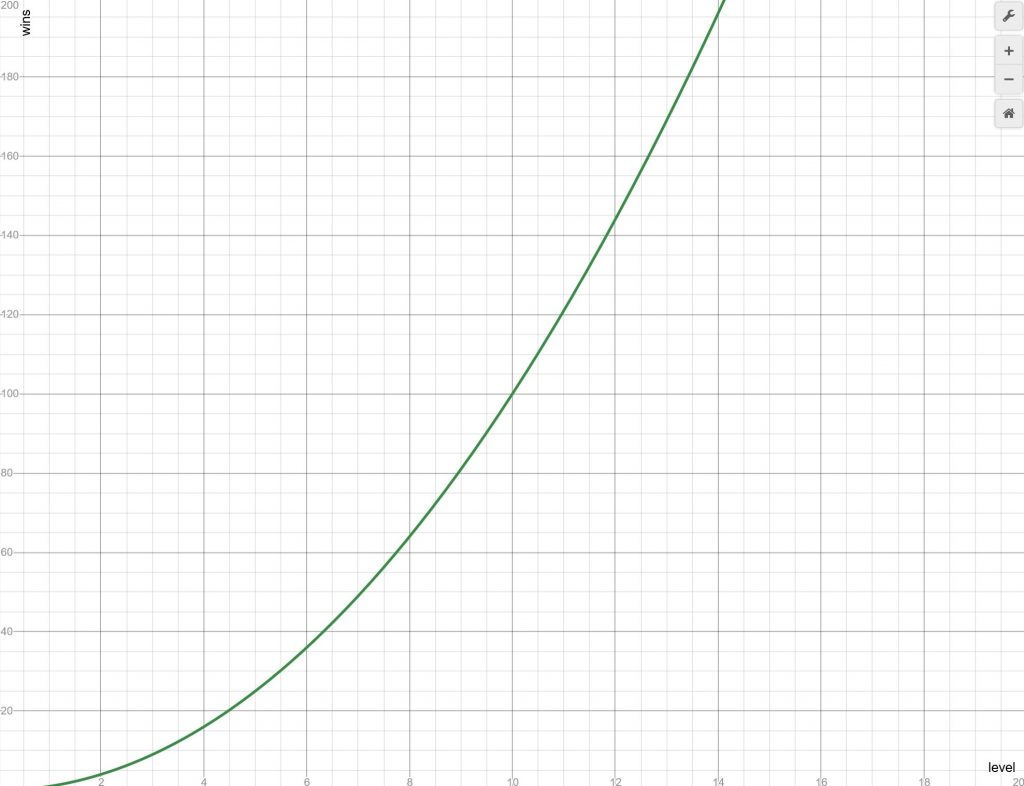
So now you know the possibilities of some of the different systems here’s what we did. Since we weren’t scaling points, a win is just a win after all, we went with a modified doubling approach. We wanted the levels to start at 1, even if you’d not won anything, and then increase slowly – the gap to the next level should be twice the current level. This sounds like it should be easy:
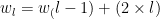
However, to determine the wins needed per level in this form would need recursion, which is a bad thing for performance4. So, as I’ve spoken about before with making AI efficient, you can turn this sort of thing into a nice simple equation.

If you extrapolate this back you should be able to see that the wins needed is a sum:
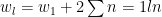
But this is still an annoying recursion. However, thanks to Gauss there’s a simple formula for getting the answer when you add consecutive numbers:
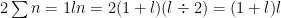
So for any level:
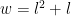
but if we want to start with level 1 for zero wins we need to take 2 from this to fix our starting level:

This gives us the following levels:
| Level | Wins needed |
| 1 | 0 |
| 2 | 4 |
| 3 | 10 |
| 4 | 18 |
| 5 | 28 |
| 6 | 40 |
| 7 | 54 |
| 8 | 70 |
| 9 | 88 |
| 10 | 108 |
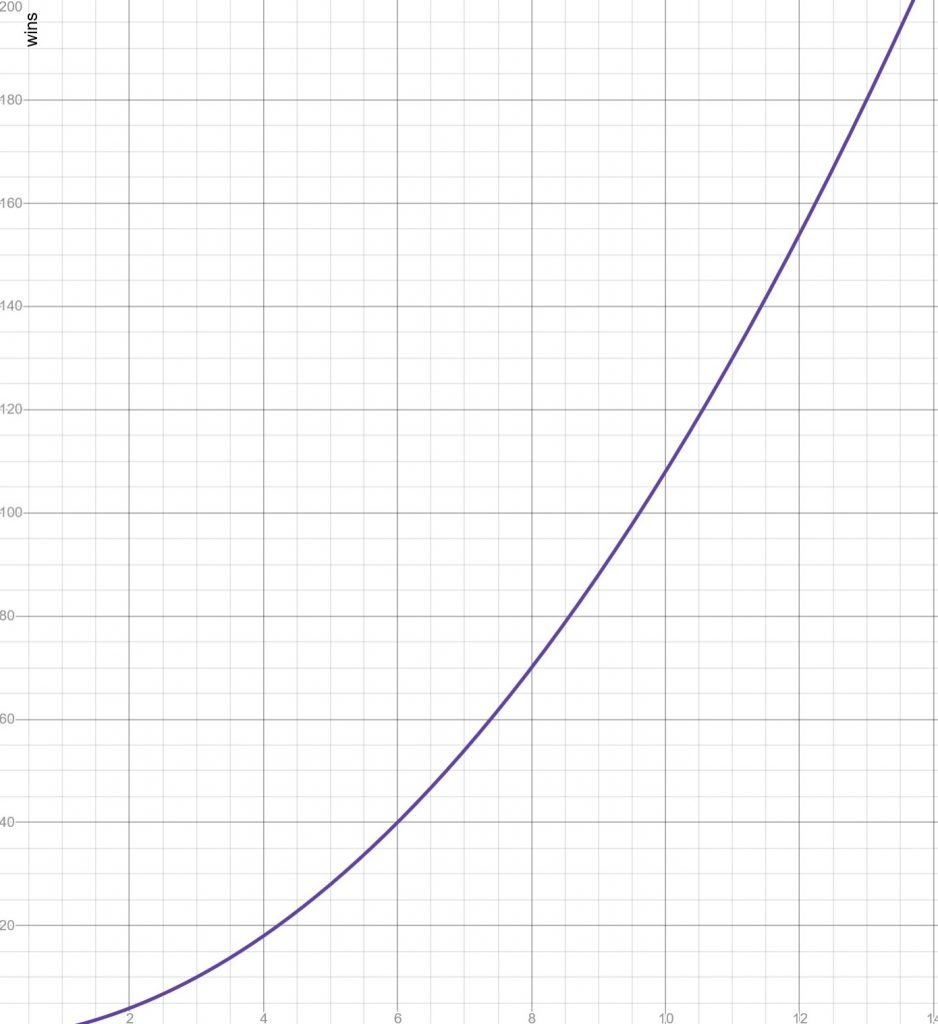
This is great – a nice gentle nonlinear increase. Converting back to level from wins looks more complicated. But we have a quadratic so we can use the formula to solve it.
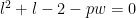
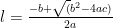
Here we have 
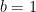


And finally for wins to next level:
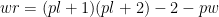
Putting this in code we have:
for l in range(20):
if l == 0:
#we start at level 1
continue
w = (l * (l + 1)) -2
print("level {} needs {} wins".format(l,w))
# get wins for a user and calculate level
for player in database:
pl = math.floor((math.sqrt(1 + (4 * (player['wins'] + 2))-1)/2)) #round the level down to the nearest int
wr = (pl + 2)*(pl + 1) - 2 - pw
print("{}, you are level {} and need {} wins to get to the next level".format(player['name'], pl, wr))If you are doing single point increments then stick with this. You could always play around by adding or removing a factor in the initial wins calculation. Here’s all the equations together:
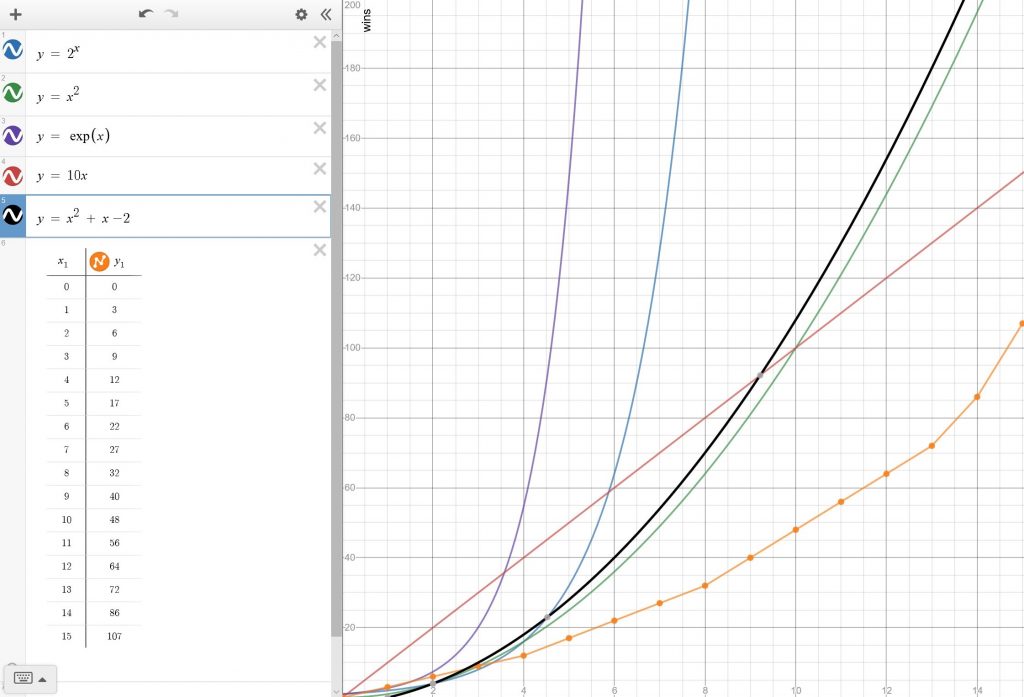
Alternatively, if you are doing experience for example where you are adding larger amounts with each “win” then you may want to try one of the alternative forms. Try the example code from github and play around with it until you get the scale you want. Any of these systems can also be scaled linearly.
- It’s this or C and not gentle C++ but original C 😉 if you want it in another language then feel free to convert it. ↩
- I know this is a trite example, but I object to hard coded numbers as it’s just storing trouble for later. ↩
- Although they’ll spot it if they know maths 😉 ↩
- I know in our case this was a very slight overhead, but good principles should always come first. ↩